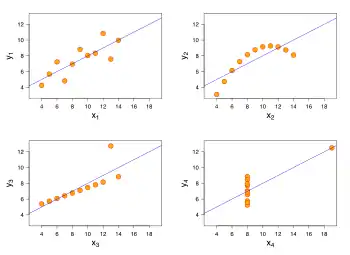
Współczynnik determinacji R² – jedna z miar jakości dopasowania modelu do danych uczących. Jego dopełnieniem jest współczynnik zbieżności, Występuje obecnie w wielu wariantach stosujących różnorodne poprawki. Jego pierwotne opracowanie przypisuje się m.in. publikacji Sewalla Wrighta z 1921, która opiera się z kolei m.in. na artykule K. Pearsona z 1897[1].

Obecnie, współczynnik determinacji wykorzystuje się głównie w celach pomocniczych. Lepszymi narzędziami do tego celu są np. kryteria informacyjne AIC, BIC, czy sprawdzian krzyżowy. Już Wright nie przedstawiał R² jako wyczerpującej miary dopasowania modelu do badanego zjawiska, szczególnie nie w sensie wyjaśnienia przyczynowego. Współczynnik determinacji opisuje jedynie oszacowaną na podstawie próby macierz wielokrotnej korelacji obecnych w modelu zmiennych, przy założeniu prawdziwości modelu. Ignoruje dopasowanie modelu do danych spoza próby, oraz problem pominiętych zmiennych. Maksymalizacja tej miary prowadzi do nadmiernego dopasowania modelu do danych uczących[2][3][4][5]. Schmueli uznaje w tym kontekście tradycję opisywania korelacji zmiennych jako ich wzajemnego wyjaśniania lub determinacji – co może sugerować wytłumaczenie przyczynowe – za szczególnie zwodniczą[6].
Współczynnik determinacji
Informuje o tym, jaka część zmienności (wariancji) zmiennej objaśnianej w próbie pokrywa się z korelacjami ze zmiennymi zawartymi w modelu. Jest on więc miarą stopnia, w jakim model pasuje do próby. Współczynnik determinacji przyjmuje wartości z przedziału [0;1] jeśli w modelu występuje wyraz wolny, a do estymacji parametrów wykorzystano metodę najmniejszych kwadratów. Jego wartości najczęściej są wyrażane w procentach. Dopasowanie modelu jest tym lepsze, im wartość R² jest bliższa jedności. Wyraża się on wzorem:

gdzie:
- – -ta obserwacja zmiennej
- – wartość teoretyczna zmiennej objaśnianej (na podstawie modelu),
- – średnia arytmetyczna empirycznych wartości zmiennej objaśnianej.





Interpretacja
Współczynnik ma jasną interpretację tylko w sytuacji, gdy współczynniki modelu zostały wyestymowane metodą najmniejszych kwadratów i w modelu występuje wyraz wolny. Wówczas i R^2 można interpretować jako miarę dopasowania modelu do danych.



Dowód.
![{\displaystyle {\begin{aligned}&\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}\\[1ex]={}&\sum _{i=1}^{n}(y_{i}-{\hat {y}}_{i}+{\hat {y}}_{i}-{\overline {y}})^{2}\\[1ex]={}&\sum _{i=1}^{n}(y_{i}-{\hat {y}}_{i})^{2}+\sum _{i=1}^{n}({\hat {y}}_{i}-{\overline {y}})^{2}+2\sum _{i=1}(y_{i}-{\hat {y}}_{i})({\hat {y}}_{i}-{\overline {y}}).\end{aligned}}}](../I/370bf10c2e271f97dd69fc2ca58b481c0a45327f.svg)
Ostatnią sumę możemy rozpisać

Pierwsza z tych sum jest równa
![{\displaystyle {\begin{aligned}&\sum _{i=1}^{n}(y_{i}-{\hat {y}}_{i}){\hat {y}}_{i}\\[1ex]={}&{\hat {y}}^{T}(y-{\hat {y}})\\[1ex]={}&{\hat {\beta }}^{T}X^{T}(y-{\hat {y}})\\[1ex]={}&{\hat {\beta }}^{T}X^{T}(y-X{\hat {\beta }})\\[1ex]={}&{\hat {\beta }}^{T}X^{T}y-{\hat {\beta }}^{T}X^{T}X{\hat {\beta }}\\[1ex]={}&{\hat {\beta }}^{T}X^{T}y-{\hat {\beta }}^{T}X^{T}X(X^{T}X)^{-1}X^{T}y=0.\end{aligned}}}](../I/a5ffff442bde35835d717628105293573cd9629d.svg)
Z powyższego rachunku wynika także, że w metodzie najmniejszych kwadratów macierz jest ortogonalna do wektora reszt tzn.



Jeżeli w modelu występuje wyraz wolny, to macierz zwiera kolumnę, a macierz – rząd jedynek. W takiej sytuacji tożsamość implikuje równość



i otrzymujemy

Wówczas

Współczynnik zbieżności
Współczynnik zbieżności określa, jaka część zaobserwowanej w próbie zmienności zmiennej objaśnianej nie pasuje do modelu (mieści się w jego błędzie). Współczynnik zbieżności przyjmuje wartości z przedziału [0;1]; wartości te najczęściej są wyrażane w procentach. Dopasowanie modelu jest tym lepsze, im wartość jest bliższa zeru. Wyraża się on wzorem:


lub też (jeżeli w modelu występuje wyraz wolny, a współczynniki zostały wyestymowane metodą najmniejszych kwadratów)
![{\displaystyle {\begin{aligned}\varphi ^{2}&=1-R^{2}\\[1ex]&={\frac {\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}}{\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}}}-{\frac {\sum _{i=1}^{n}({\hat {y}}_{i}-{\overline {y}})^{2}}{\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}}}\\[1em]&={\frac {\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}-\sum _{i=1}^{n}({\hat {y}}_{i}-{\overline {y}})^{2}}{\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}}}\\[1ex]&={\frac {\sum _{i=1}^{n}(y_{i}-{\hat {y}}_{i})^{2}}{\sum _{i=1}^{n}(y_{i}-{\overline {y}})^{2}}},\end{aligned}}}](../I/7356fa0651504327bb75598ef70b2b3a057e25e4.svg)
gdzie oraz są określone jak w części poprzedniej.

Przypisy
- ↑ Sewall Wright, Correlation and causation, „Journal of agricultural research”, 20 (7), 1921, s. 557–585.
- ↑ Norman H. Anderson, James Shanteau, Weak inference with linear models., „Psychological Bulletin”, 84 (6), 1977, s. 1155–1170, DOI: 10.1037/0033-2909.84.6.1155, ISSN 0033-2909 [dostęp 2019-03-28] (ang.).
- ↑ Michael H. Birnbaum, The devil rides again: Correlation as an index of fit., „Psychological Bulletin”, 79 (4), 1973, s. 239–242, DOI: 10.1037/h0033853, ISSN 1939-1455 [dostęp 2019-03-28] (ang.).
- ↑ James Shanteau, Correlation as a deceiving measure of fit, „Bulletin of the Psychonomic Society”, 10 (2), 1977, s. 134–136, DOI: 10.3758/BF03329303, ISSN 0090-5054 [dostęp 2019-03-28] (ang.).
- ↑ Andrej-Nikolai Spiess, Natalie Neumeyer, An evaluation of R2 as an inadequate measure for nonlinear models in pharmacological and biochemical research: a Monte Carlo approach, „BMC Pharmacology”, 10 (1), 2010, DOI: 10.1186/1471-2210-10-6, ISSN 1471-2210, PMID: 20529254, PMCID: PMC2892436 [dostęp 2019-03-28] (ang.).
- ↑ Galit Shmueli, To Explain or to Predict?, „Statistical Science”, 25 (3), 2010, s. 289–310, DOI: 10.1214/10-STS330, ISSN 0883-4237 [dostęp 2019-03-28] (ang.).