Metryka oprogramowania – miara pewnej własności oprogramowania lub jego specyfikacji. Termin ten nie ma precyzyjnej definicji i może oznaczać właściwie dowolną wartość liczbową charakteryzującą oprogramowanie[1].
Standard IEEE 1061-1998 określa metrykę jako funkcję odwzorowującą jednostkę oprogramowania w wartość liczbową. Ta wyliczona wartość jest interpretowalna jako stopień spełnienia pewnej własności jakości jednostki oprogramowania[2]. Metryki używają różnych definicji jednostki oprogramowania, opartej zazwyczaj na kodzie źródłowym, rozdzielonym na jeden lub więcej plików. Istnieją też metryki, które nie bazują na kodzie, lecz pozwalają na analizę specyfikacji oprogramowania (np. punkty funkcyjne) lub przebiegu wykonania programu.
Zastosowanie
Celem użycia metryk oprogramowania jest otrzymanie dokładnych wartości, które dotyczą wytwarzanych aplikacji. Lord Kelvin, fizyk i matematyk, stwierdził: Jeśli to o czym mówisz potrafisz zmierzyć i wyrazić w liczbach – wiesz coś o tym. Inaczej twa wiedza jest mizerna[3], inżynier oprogramowania Tom DeMarco uważa zaś, że nie można kontrolować tego, czego się nie da zmierzyć[4]. Metryki pozwalają na obiektywne spojrzenie na oprogramowanie i porównanie ze sobą poszczególnych jego elementów lub różnych produktów. Mierzenie jakości aplikacji oraz wydajności pracy bez danych liczbowych staje się bardzo trudne, a utrzymanie obiektywności jest niemal niemożliwe.
Obliczanie metryk jest istotnym ułatwieniem we wszystkich fazach procesu wytwarzania oprogramowania. W fazie projektowania metodologie takie jak COCOMO za pomocą rozmaitych metryk pozwalają na oszacowanie nakładu pracy potrzebnego do realizacji pomysłu. Na tym etapie metryki są przydatne przede wszystkim dla klientów oraz projektantów. W fazie produkcji dużą rolę odgrywają metryki statyczne, pomagające w utrzymywaniu jakości kodu źródłowego. Korzystają na tym programiści, którzy dzięki metrykom mogą łatwo odnajdywać te miejsca w kodzie, które są potencjalnym źródłem nadmiernej złożoności, a co za tym idzie, powstających błędów. W fazie testów wykorzystywane są zarówno metryki statyczne, jak i dynamiczne, pozwalające na badanie przebiegu wykonania programu. Na tym etapie gromadzone są też dane liczbowe dotyczące wydajności czy niezawodności aplikacji. Wyniki testów są pożytecznym źródłem informacji dla wszystkich osób zaangażowanych w projekt, w tym kierowników, programistów i klientów.
Jakość metryki
Istotną kwestią jest ocena samej metryki („meta-metryka”). Aby metryka była użyteczna, powinna być:
- prosta i możliwa do obliczenia przez komputer
- przekonująca
- konsekwentna i obiektywna
- spójna pod względem użytych jednostek
- niezależna od języka programowania
- dająca przydatne informacje[5].
Linda Westfall wymienia 12 kroków prowadzących do opracowania użytecznych metryk:
- identyfikacja klientów,
- ustalenie celów,
- zadanie pytań,
- wybór metryk,
- standaryzacja definicji,
- wybór funkcji mierzącej,
- ustalenie metody pomiaru,
- definicja kryteriów wyboru,
- definicja mechanizmów raportowania,
- ustalenie dodatkowych własności,
- zebranie danych,
- aspekt ludzki[1].
Charakterystycznym elementem jest paradygmat Cel – Pytanie – Metryka (GQM, Goal – Question – Metrics), wypromowane przez Victora Basiliego z University of Maryland oraz Laboratorium Inżynierii Oprogramowania Centrum Lotów Kosmicznych imienia Roberta H. Goddarda. Polega ono na ustaleniu trzech kroków: pierwszym jest zdefiniowanie celów projektu, drugim ustalenie pytań, na które trzeba odpowiedzieć w trakcie realizacji, trzecim wykonanie odpowiednich pomiarów, dostosowanych odpowiednio do pierwszych dwóch poziomów[6]. Metryka powinna być ściśle dopasowana do tego, jakie informacje są potrzebne w trakcie procesu tworzenia produktu. Używanie wyłącznie metryk ogólnych może być mylące, a nawet niebezpieczne[7].
Podział
Podstawowy podział metryk oprogramowania związany jest ze sposobem podejścia do jego analizy i testowania. Podobnie jak testy dzielą się na testy strukturalne (testy białej skrzynki) oraz testy funkcjonalne (testy czarnej skrzynki), tak też można podzielić metryki na związane z analizą kodu źródłowego metryki statyczne oraz metryki dynamiczne, wyznaczane w oderwaniu od kodu i badające zachowanie uruchomionego programu. Osobną kategorią są metryki niezwiązane bezpośrednio z implementacją oprogramowania, lecz z jego specyfikacją, wymaganiami klienta, a także z przebiegiem testów.
Inne podejście dzieli metryki ze względu na obiekty i wartości je charakteryzujące, jakie są przez nie mierzone. Można wyróżnić metryki produktów, takie jak metryki rozmiaru (size metrics), metryki złożoności (complexity metrics) czy metryki jakości (quality metrics). Innymi metrykami są metryki procesów (process metrics), metryki zasobów (resource metrics) czy metryki projektu (project metrics)[4]. Wyraźny jest tu podział na metryki produktów, dotyczące właściwości samego oprogramowania, oraz metryki procesów, charakteryzujące proces jego wytwarzania.
Metryki mogą mierzyć wartości bezpośrednio (np. liczba linii kodu) lub pośrednio, najpierw obliczając wartości składowe (np. częstość występowania błędów = liczba błędów / całkowity rozmiar produktu), mogą też bazować na subiektywnych prognozach (np. punkty funkcyjne)[4].
Metryki statyczne
Metryki statyczne pozwalają na ocenę jakości kodu źródłowego i łączą się ściśle z analizą statyczną, dziedziną inżynierii oprogramowania zajmującą się badaniem struktury kodu źródłowego. Metryki te najbardziej przydatne są dla samych programistów i innych osób bezpośrednio zaangażowanych w proces powstawania oprogramowania. Pozwalają na bieżące śledzenie jakości kodu i zwrócenie uwagi na miejsca, które wymagają uproszczenia bądź szczególnie uważnego testowania.
Metryki rozmiaru
Linie kodu
Najprostszą metryką rozmiaru oprogramowania jest liczba linii kodu źródłowego, oznaczana jako LOC (lines of code) lub SLOC (source lines of code). Wielkość ta daje ogólne pojęcie o skali programu, nie jest jednak wystarczająca do bardziej szczegółowych analiz. Wartość LOC jest silnie zależna od użytego języka programowania – ten sam algorytm w języku wysokiego poziomu będzie miał wielokrotnie mniej linii kodu niż w asemblerze.
Istotny jest też sposób zliczania linii kodu – ich liczba może się zdecydowanie zmieniać, zależnie od tego, czy wliczane są puste linie, komentarze czy linie zawierające jedynie nawiasy klamrowe (m.in. w językach C, Java czy PHP) bądź słowa kluczowe begin i end (w Pascalu). Liczba linii z pominięciem wymienionych elementów jest określana jako eLOC (effective lines of code).
Alternatywą dla zliczania fizycznych linii kodu jest miara logicznych linii kodu, oznaczana jako lLOC (logical lines of code). Miara ta jest zależna od użytego języka programowania, np. w C zliczane są linie zakończone średnikami[8].
W większych projektach używane są jednostki pochodne takie jak KLOC (kilo-LOC).
Liczba tokenów
Podstawową wadą liczby linii kodu jako metryki jest fakt, że nie odróżnia ona w żaden sposób trudnych i łatwych części kodu źródłowego oraz premiuje rozwlekły styl pisania programów. Aby nadać odpowiednie wagi mniej i bardziej skomplikowanym liniom kodu, można zastosować inną metrykę, mierzącą liczbę tokenów – czyli podstawowych jednostek składni języka programowania. Schemat takiej metryki został użyty po raz pierwszy w 1977 przez Maurice’a Howarda Halsteada w jego rodzinie metryk zwanej metrykami Halsteada[9], a przez niego samego nazwanych Software Science. Halstead rozróżnił dwa typy tokenów, na które można podzielić całość kodu źródłowego (bez komentarzy). Są to operatory (symbole i słowa kluczowe symbolizujące pewną akcję) i operandy (zmienne, stałe itp.). Na ich podstawie można określić podstawowe metryki:
- – liczba unikatowych operatorów
- – liczba unikatowych operandów
- – całkowita liczba wystąpień operatorów
- – całkowita liczba wystąpień operandów.




Reguły klasyfikowania symboli jako operatorów i operandów są zależne od języka programowania. Na podstawie tych podstawowych wartości można określić kolejne, bardziej złożone:
- = słownictwo (vocabulary)
- = długość (length)
- = objętość (volume)[9].



Badania wskazały, że wartości N i V są liniowo powiązane z liczbą linii kodu, mierzą więc tę samą wielkość. Charakteryzuje je jednak wyższa odporność na małe zmiany w kodzie. Halstead zaproponował też kolejne metryki, dotyczące już nie tylko rozmiaru, ale i złożoności programu, o których jest mowa poniżej.
Inne metryki
Szeroko stosowane są jednostki rozmiaru programu większe niż linie kodu. Dla większych aplikacji często stosowanymi metrykami są liczba modułów czy liczba funkcji. Ponieważ obecnie dominującym paradygmatem programowania jest podejście obiektowe, wytworzono wiele metod mierzenia oprogramowania dla niego specyficznych (zob. metryki obiektowe). Podstawowymi metrykami rozmiaru dla projektów obiektowych są np. liczba klas i interfejsów.
Na podstawie linii kodu można wyliczyć wiele metryk pochodnych, takich jak produktywność (KLOC / osobomiesiąc), jakość (błędy / KLOC), koszt (koszt / KLOC) czy ilość dokumentacji (strony dokumentacji / KLOC)[10]. Należy pamiętać, że zawsze będą one miały jedynie charakter pomocniczy i niedopuszczalne jest np. ocenianie pracowników wyłącznie na podstawie liczby napisanych linii kodu[11].
Podstawowe metryki złożoności
Sam rozmiar programu jest informacją przydatną, jednak daje zbyt mało wiedzy na jego temat. Aby scharakteryzować oprogramowanie pod względem jego złożoności, trzeba użyć innych metod. Jeśli użyte są wyrafinowane algorytmy, cenną miarą będzie ich złożoność obliczeniowa. Wartość ta ma kluczowe znaczenie w badaniu wydajności, często daje jednak informacje o małym wycinku kodu źródłowego. Metryki mierzące złożoność opierają się na strukturze kodu źródłowego.
Złożoność cyklomatyczna McCabe’a
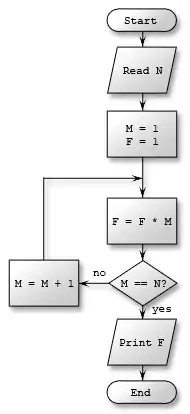
8 węzłów, 8 krawędzi,
CC = 8 – 8 + 2 = 2
Jedną z najbardziej podstawowych metryk złożoności jest złożoność cyklomatyczna (cyclomatic complexity number, ozn. CC lub v(G)), zaproponowana przez Thomasa J. McCabe’a w 1976[12]. Pierwotnie pomyślana była jako metryka dla programów strukturalnych, nadaje się jednak równie dobrze do programów obiektowych, dzięki czemu jest popularna także dzisiaj. Złożoność cyklomatyczna jest liczbą charakteryzującą funkcję lub metodę i odzwierciedlającą jej poziom skomplikowania.
Początkowo złożoność cyklomatyczna miała mierzyć liczbę niezależnych ścieżek przebiegu programu, co bezpośrednio przekłada się na łatwość jego przetestowania. Ponieważ skoki wstecz mogą spowodować nieskończony wzrost takich ścieżek, mierzy się liczbę prostych ścieżek bez uwzględniania cykli.
Złożoność cyklomatyczną dla danej funkcji można policzyć, mając do dyspozycji graf przebiegu programu. Wówczas wyraża się ona wzorem

gdzie oznacza liczbę krawędzi, a liczbę wierzchołków w grafie. Inny wzór podaje prostą zależność CC od liczby węzłów, w których podejmujemy decyzje:



gdzie to liczba węzłów decyzyjnych, w których podejmowana jest decyzja o charakterze binarnym (tak/nie).

Taki wzór pozwala na szybkie wyznaczanie wartości CC – wystarcza tu zliczyć liczbę wystąpień słów kluczowych if, while, for czy case.
Niska wartość CC wskazuje na łatwość zrozumienia danej funkcji czy metody. Wartość powyżej 20 charakteryzuje złożony kod i wiąże się z dużym ryzykiem wystąpienia błędów.
Zaletami metryki CC są m.in. łatwość jej obliczenia i możliwość wskazania elementów aplikacji, które należy przeprojektować. Liczba rozgałęzień przepływu programu nie daje jednak pełnej informacji, ponieważ nie rozróżnia zagnieżdżonych i niezagnieżdżonych pętli oraz prostych instrukcji case, a także nie bierze pod uwagę skomplikowanych warunków w węzłach decyzyjnych. Istnieją modyfikacje definicji CC, które pozwalają zredukować lub wyeliminować te wady[13].
Złożoność Halsteada
Wspomniane wyżej metryki Halsteada dotyczące rozmiaru programu pozwalają na zdefiniowanie bardziej skomplikowanych metryk złożoności. Wyróżnia się wśród nich:
| trudność (difficulty), czyli podatność na błędy, proporcjonalna do liczby unikatowych operatorów a także do stosunku pomiędzy wszystkimi a unikatowymi operandami | |
| poziom programu (program level), im niższy, tym bardziej aplikacja jest podatna na błędy | |
| wysiłek (effort) potrzebny do zaimplementowania programu, proporcjonalny do trudności oraz objętości | |
| czas (time) potrzebny do zaimplementowania, wyrażony w sekundach – współczynnik 18 został wyznaczony eksperymentalnie i jest modyfikowalny indywidualnie dla danego programisty | |
| szacunkowa liczba błędów (number of delivered bugs) – wartość ta jest zależna od użytego języka programowania, jest na przykład wyższa dla aplikacji w C lub C++ |









Niniejsze wartości mimo oczywistej niedokładności stanowią cenną informację podczas etapu testowania aplikacji – przykładowo wartość w porównaniu z rzeczywistą liczbą znalezionych błędów może dać wskazówki na temat efektywności przeprowadzonych testów.

Metryki obiektowe
Z powodu wzrostu popularności programowania obiektowego w latach 90. należało wprowadzić metryki adekwatne do tego podejścia.
Zestaw metryk CK
Popularnym zestawem metryk jest grupa sześciu metryk autorstwa Shyama R. Chidambera i Chrisa F. Kemerera, zaprojektowana specjalnie dla oprogramowania obiektowego w 1991 i ulepszona w 1994[14]. Od nazwisk autorów metryki te nazywane są zestawem metryk CK. Opisują one relacje pomiędzy klasami oraz ich złożoność i jej wpływ na utrzymywalność kodu. Ponieważ bazują one na analizie drzewa dziedziczenia oraz pojedynczych klas, nie nadają się do przewidywania czasu czy wysiłku koniecznego do implementacji, służą raczej projektantowi programiście jako informacje wskazujące potencjalne słabe punkty architektury systemu. Zestaw zawiera następujące metryki:
- Weighted Methods per Class (WMC)
- Depth of Inheritance Tree (DIT)
- Number of Children (NOC)
- Coupling Between Objects (CBO)
- Response For a Class (RFC)
- Lack of Cohesion of Methods (LCOM).
WMC
Metryka Weighted Methods per Class (WMC, tłum. na polski: uśrednione metody na klasę) zlicza metody występujące w danej klasie:

gdzie jest pewną miarą złożoności metody ( to kolejne metody w klasie). Jeśli za wstawimy stałą 1, wynik będzie prostym zliczeniem wszystkich metod. W wariancie tej metryki za należy wstawić złożoność cyklomatyczną danej metody.




DIT
Metryka Depth of Inheritance Tree (DIT, głębokość drzewa dziedziczenia) pozwala na określenie stopnia dziedziczenia – dla danej klasy wartością DIT jest liczba kolejnych klas, po których dziedziczy dana klasa. Jeśli występuje dziedziczenie wielokrotne, to wartością DIT jest najdłuższa ścieżka do korzenia (w przypadku języka Java korzeniem tym jest klasa Object, a wszystkie klasy mają DIT równe co najmniej 1).
Wynik tej metryki może być różnie interpretowany. Z jednej strony dziedziczenie pozwala na ponowne użycie kodu, z drugiej klasy o wysokim DIT mogą być przeładowane dziedziczonymi metodami. Rekomendowane jest DIT nieprzekraczające 6[15].
NOC
Metryka Number of Children (NOC, liczba dzieci) polega na zliczaniu – w zależności od definicji – wszystkich lub tylko bezpośrednich podklas danej klasy. Podczas gdy DIT mierzy głębokość hierarchii dziedziczenia, NOC mierzy jej szerokość. Z powodu możliwości powtórnego użycia kodu lepsze jest głębokie drzewo dziedziczenia, dlatego wysoka wartość NOC może świadczyć o nieprawidłowym użyciu tego mechanizmu. Prawidłowe wartości NOC wahają się w przedziale od 2 do 5, wartości wyższe powodują problemy z pielęgnacją systemu.
CBO
Metryka Coupling Between Objects (CBO, zależność między obiektami) pozwala na określenie stopnia zależności klasy z innymi klasami niebędącymi jej przodkami ani klasami potomnymi. Jej wartością jest liczba odwołań do innych klas w obrębie metod i atrybutów danej klasy. Nie zalicza się tutaj odwołań do typów prymitywnych (int czy boolean) oraz podstawowych typów systemowych (w Javie: java.lang.*).
Wysoka wartość CBO wskazuje na nieprawidłowości – obiekty stają się wówczas zbyt zależne od innych.
RFC
Response For a Class (RFC, odpowiedzialność danej klasy) jest miarą potencjalnej komunikacji pomiędzy klasą a jej środowiskiem:

gdzie oznacza całkowitą liczbę metod w klasie (total methods), – liczbę podklas (total subclasses), a – całkowitą liczbę metod w podklasie Jest to więc liczba metod, które mogą potencjalnie zostać wysłane w odpowiedzi na dowolny komunikat wysłany do obiektu danej klasy. Wysoka wartość RFC oznacza większą funkcjonalność, ale zarazem i wyższą złożoność. Należy unikać zbyt wysokich wartości RFC, które zazwyczaj utrudniają weryfikację i testowanie klasy.




LCOM
Lack of Cohesion of Methods (LCOM, brak spójności metod) jest metryką wskazującą na brak pożądanej własności klas, jaką jest ich spójność. Klasa powinna mieć ściśle określone pole działania i pełnić jedną dobrze wybraną funkcję. Brak spójności oznacza, że klasa wykonuje więcej niż jedną funkcję i powinna zostać podzielona, aby umożliwić prawidłową hermetyzację.
Występują cztery warianty metryki LCOM[16]:
- LCOM1 (Chidamber & Kemerer)
- Pierwotna wersja metryki LCOM. Dla każdej pary metod w klasie sprawdzamy, czy mają one dostęp do rozłącznych zbiorów zmiennych instancyjnych. Jeśli tak jest, należy zwiększyć o 1, w przeciwnym razie należy zwiększyć o 1. Wartością LCOM będzie
- Metryka LCOM1 była krytykowana ze względu m.in. na mało dokładne wyniki i błędne pojmowanie spójności klasy, dlatego zaproponowano kolejne wersje metryki.
- LCOM2 oraz LCOM3 (Henderson-Sellers, Constantine & Graham)
- Metryki LCOM2 i LCOM3, podobnie jak LCOM1, mierzą poziom spójności klasy i w nich także pożądana jest niska wartość. LCOM2 przyjmuje wartości z zakresu [0, 1], zaś LCOM3 z zakresu [0, 2]. W metrykach tych użyte są definicje:
- = liczba metod w klasie
- = liczba atrybutów w klasie
- = liczba metod mających dostęp do atrybutu
- = suma wartości po wszystkich atrybutach
- Wówczas a
- LCOM4 (Hitz & Montazeri)
- Metryka LCOM4 pozwala na zmierzenie liczby spójnych składowych części klasy. Każda spójna składowa to pewien zbiór powiązanych ze sobą metod i atrybutów. Metody są ze sobą powiązane, jeśli mają dostęp do tego samego atrybutu lub jeśli jedna z nich wywołuje drugą.
- Optymalną wartością LCOM4 jest 1. Wyższe wartości wskazują na konieczność podziału klasy, zaś wartość zerowa oznacza brak jakichkolwiek metod.










Zestaw metryk MOOD
Zestaw MOOD (Metrics for Object-Oriented Design) został utworzony nieco później (1995) przez Fernando Brito e Abreu. Metryki te mają służyć całościowej ocenie systemu, a wyrażone są w procentach oznaczających stopień wykorzystania mechanizmów charakterystycznych dla programowania obiektowego. Zestaw MOOD jest niezależny od języka programowania oraz jest dobrze skalowalny.
Metryki MOOD mierzą następujące elementy:
- polimorfizm
- Polymorphism Factor (PF)
- hermetyzacja
- Attribute Hiding Factor (AHF)
- Method Hiding Factor (MHF)
- dziedziczenie
- Attribute Inheritance Factor (AIF)
- Method Inheritance Factor (MIF)
- przekazywanie komunikatów
- Coupling Factor (CF).
W późniejszym okresie powstały metryki MOOD2 – rozszerzenie standardowego zestawu MOOD. Wykorzystywane przez ten wariant metryki to:
- OHEF: Operation Hiding Effectiveness Factor
- AHEF: Attribute Hiding Effectiveness Factor
- IIF: Internal Inheritance Factor
- PPF: Parametric Polymorphism Factor[17].
Metryki pakietów
Metryki pakietów badają oprogramowanie na poziomie pakietów – służą do oceny prawidłowości ich powiązań.
Tree impurity
Wartość metryki tree impurity (w wolnym tłumaczeniu „czystość drzewa”) powstaje na bazie grafu powiązań między poszczególnymi pakietami. Wartość ta waha się od 0 do 1 i wskazuje, jak bardzo graf jest zbliżony do drzewa. Wysokie tree impurity jest oznaką złego podziału oprogramowania na pakiety.
Jeśli jako oznaczymy liczbę krawędzi w grafie, a jako liczbę węzłów (pakietów), wartość metryki wyniesie Wartość 0% oznacza, że graf jest pełnym drzewem, zaś 100% – kliką.

Metryki Roberta C. Martina
Popularnym zestawem metryk pakietów jest grupa pięciu metryk zaprojektowana w 1994 przez Roberta Cecila Martina.
Efferent coupling
Metryka efferent coupling (w wolnym tłumaczeniu „zależność odśrodkowa”, także fan-out), oznaczana symbolem Ce, mierzy zależności wychodzące dla danej klasy lub danego pakietu. Jej wartość to liczba klas, od których rozpatrywany obiekt jest zależny. Miara ta wskazuje, które klasy i pakiety są najbardziej zależne od innych i tym samym narażone na niestabilność wobec zmian zachodzących w innych miejscach kodu. Optymalne wartości wynoszą od 0 do 20, wyższe liczby powodują problemy związane z rozwojem i pielęgnacją danego komponentu. Przykładem elementów o wysokim jest interfejs użytkownika, który musi odzwierciedlać wszelkie zmiany w logice systemu.

Afferent coupling
Metryka afferent coupling („zależność dośrodkowa”, fan-in, ozn. Ca) jest przeciwieństwem efferent coupling. Wartość ta oznacza liczbę klas, które są zależne od badanej klasy (pakietu). Im większa jest wartość tym więcej odpowiedzialności spoczywa na autorze zmian w kodzie danego komponentu. Wysokie w niejawny sposób oznacza wyższą stabilność, ponieważ wymusza ograniczenie zmian i wysoki poziom przetestowania. Liczba ta nie powinna przekraczać 500 – wyższe wartości sprawiają, że jakiekolwiek zmiany w elemencie stają się trudne do wykonania. Wysokim afferent coupling charakteryzują się np. kontrolery we wzorcu projektowym MVC.


Poziom niestabilności
Wartości i pozwalają wyznaczyć niestabilność (instability, ozn. I) danej klasy lub pakietu:

Niestabilność oznacza w tym wypadku podatność na zmiany w danym komponencie. Waha się ona pomiędzy 0 (dla elementów o wysokim afferent coupling) a 1 (dla elementów o wysokim efferent coupling). Według Roberta C. Martina klasy i pakiety dzielą się na dwie grupy – komponenty stabilne winny mieć wartość pomiędzy 0 a 0,3, natomiast niestabilne pomiędzy 0,7 a 1. Nie należy natomiast tworzyć klas i pakietów o średniej niestabilności (od 0,3 do 0,7).

Poziom abstrakcji
Kolejną metryką związaną z własnościami pakietów jest poziom abstrakcji (abstractness, ozn. A). Wartość tej metryki to odsetek klas abstrakcyjnych w stosunku do wszystkich klas, znów wahający się pomiędzy 0 a 1. Wskazane jest, by to klasy abstrakcyjne cechowały się niskim poziomem niestabilności, ponieważ jest od nich zależnych wiele podklas.
Odległość od ciągu głównego
Mając dane niestabilność i abstrakcyjność, możliwe jest obliczenie istotnego wskaźnika, jaką jest znormalizowana odległość od ciągu głównego (distance from main sequence, D):

Wartość ta odpowiada poziomowi zaburzenia równowagi pomiędzy poziomami abstrakcji i niestabilności. Klasy abstrakcyjne powinny charakteryzować się stabilnością, zaś niestabilne powinny być klasy konkretne. Dla dobrze zaprojektowanych klas wartość powinna być niska, ponieważ współczynniki oraz powinny się wzajemnie kompensować, sumując się do 1. Wysoka wartość (powyżej 0,2) jest oznaką źle zaprojektowanego podziału klas.


Zobacz też
Przypisy
- 1 2 Linda Westfall: 12 Steps to Useful Software Metrics. [dostęp 2009-06-13]. (ang.).
- ↑ IEEE Std 1061-1998 (Revision of IEEE Std 1061-1992). [dostęp 2009-06-13]. (ang.).
- ↑ Cyt. za: Ryszard Kacprzyk: Wybrane zagadnienia badań ładunku i jego zaniku w dielektrykach stałych. s. 3. [dostęp 2009-06-13].
- 1 2 3 Anthony Finkelstein: Advanced Software Engineering Course Structure. University of London. [dostęp 2009-06-13]. (ang.).
- ↑ Object-Oriented Software Engineering. Topic 14: Software Characteristics and Metrics. [dostęp 2009-06-14]. (ang.).
- ↑ Jarosław Kuchta: Jakość systemów informatycznych. Goal Question Metrics. [dostęp 2009-06-13]. [zarchiwizowane z tego adresu (9 października 2010)]. (pol.).
- ↑ Kazimierz Subieta: Wytwarzanie, integracja i testowanie systemów informacyjnych. Jakość, złożoność i miary oprogramowania. [dostęp 2009-06-13]. [zarchiwizowane z tego adresu (21 lipca 2006)].
- ↑ Source lines of code – Knowledgerush. [dostęp 2009-06-13]. (ang.).
- 1 2 Halstead metrics. [dostęp 2009-06-14]. (ang.).
- ↑ Software metrics. [dostęp 2009-06-14]. [zarchiwizowane z tego adresu (21 października 2008)]. (ang.).
- ↑ Por. np. Lionel C. Brand, Isabella Wieczorek: Resource Estimation in Software Engineering. s. 36. [dostęp 2009-06-14]. [zarchiwizowane z tego adresu (17 czerwca 2013)].
- ↑ Thomas J. McCabe: A Complexity Measure. [dostęp 2009-06-14]. (ang.).
- ↑ Complexity metrics. [dostęp 2009-06-14]. (ang.).
- ↑ Ewan Tempero, Emilia Mendes: The „CK” Metrics. [dostęp 2009-06-14]. [zarchiwizowane z tego adresu (31 marca 2010)]. (ang.).
- ↑ NDepend. Metrics definitions. [dostęp 2009-06-14]. (ang.).
- ↑ Cohesion metrics. [dostęp 2009-06-14]. (ang.).
- ↑ MOOD and MOOD2 metrics. [dostęp 2009-06-14]. (ang.).
Bibliografia
- S.D. Conte, H.E. Dunsmore, V.Y. Shen: Software engineering metrics and models. Menlo Park, Kalifornia: The Benjamin/Cummings Publishing Company, Inc., 1986. ISBN 0-8053-2162-4.
- Cem Kaner, Walter P. Bond: Software Engineering Metrics: What Do They Measure and How Do We Know?. [dostęp 2009-06-13]. (ang.).
- Zaawansowana inżynieria oprogramowania. Wykłady w serwisie edukacyjnym Ważniak. [dostęp 2009-06-13].
- Zaawansowane programowanie obiektowe. Wykłady w serwisie edukacyjnym Ważniak. [dostęp 2009-06-14].
- Metrics Definitions – Resource Standard Metrics. [dostęp 2009-06-13]. [zarchiwizowane z tego adresu (23 czerwca 2006)]. (pol.).
- ckjm – A Tool for Calculating Chidamber and Kemerer Java Metrics. [dostęp 2009-11-04]. (ang.).
- Metrics Repository – kolekcja obiektowych metryk oprogramowania. [dostęp 2010-11-17]. (ang.).