Algorytm Earleya – algorytm służący do analizy składniowej na podstawie dowolnej gramatyki bezkontekstowej. Stosuje się go między innymi do przetwarzania języków naturalnych[1][2], gdyż inaczej niż większość algorytmów analizy składniowej działa również z gramatykami niejednoznacznymi. Korzysta się też z niego przy tworzeniu interpreterów i kompilatorów języków programowania, zwłaszcza języków specjalizowanych, ponieważ szkielety projektowe oparte na tym algorytmie ułatwiają szybkie tworzenie prototypów (RAD)[3][4].
Górne ograniczenie czasu analizy n symboli terminalnych przez parser oparty na tym algorytmie rośnie proporcjonalnie do n3 w ogólnym przypadku, do n2 dla gramatyk jednoznacznych i do n dla sporej klasy gramatyk bezkontekstowych, w tym większości gramatyk języków programowania.
Algorytm ten opracował w 1968 roku Jay Earley z Carnegie Mellon University w swojej pracy doktorskiej[5] promowanej przez Roberta W. Floyda. W 1970 roku Earley opublikował go w Communications of the ACM w artykule[6], który w 1983 roku zaliczono do 21 najbardziej znaczących publikacji w ćwierćwieczu istnienia tego czasopisma[7].
Zasada działania
Algorytm Earleya należy, podobnie jak algorytm CYK, do klasy tablicowych metod analizy składniowej (ang. chart parsers). Stosuje się w nim wstępującą analizę składniową z lewa na prawo na podstawie zstępujących przewidywań. Wyniki algorytmu powstają na podstawie wcześniejszych wyników częściowych, zgodnie z techniką programowania dynamicznego.
Analiza składniowa z zastosowaniem tego algorytmu operuje na zbiorze sytuacji Earleya (ang. Earley items) lub krótko sytuacji, czyli produkcji gramatyki z dodaną kropką i dwoma indeksami. Podczas działania algorytmu sytuacje Earleya odzwierciedlają dotychczas zastosowane produkcje oraz służą do przewidywania kolejnych produkcji. Po przeanalizowaniu poprawnego ciągu wejściowego powinna powstać sytuacja, która odzwierciedla jego wyprowadzenie z symbolu startowego gramatyki.
Sytuacje Earleya mają postać [A →h X0 … Xp−1 •i Xp … Xq−1], gdzie produkcja A → X0 … Xq−1 należy do zbioru produkcji danej gramatyki. Indeksy przy strzałce →h i kropce •i spełniają nierówności 0 ≤ h ≤ i ≤ n (jeśli symbole terminalne ponumerować od t0 do tn−1), a kropka może leżeć gdziekolwiek pomiędzy początkiem a końcem prawej strony produkcji A → X0 … Xq−1 włącznie, czyli 0 ≤ p ≤ q. Indeks h określa pierwszy symbol terminalny wchodzący do drzewa rozbioru danej produkcji, indeks i – pierwszy nierozpatrzony jeszcze symbol terminalny, a położenie kropki oznacza postęp analizy danej produkcji. Ujmując rzecz formalnie, sytuacja Earleya [A →h X0 … Xp−1 •i Xp … Xq−1] oznacza, że algorytm przeanalizował podciąg t0 … ti−1 jako część formy zdaniowej t0 … th−1X0 … Xq−1α do symbolu Xp−1 włącznie (małe litery greckie α, β, γ, ... oznaczają dowolne, także puste ciągi symboli terminalnych lub nieterminalnych).
Na początku działania algorytmu zbiór sytuacji zawiera jeden element [S’ →0 •0 S], gdzie S oznacza właściwy symbol startowy danej gramatyki, a S’ – pomocniczy symbol startowy spoza zbioru symboli gramatyki. Następnie dopóty, dopóki ten zbiór rośnie, algorytm dodaje do niego nowe sytuacje na podstawie wejściowych symboli terminalnych i sytuacji już należących do zbioru. Jeżeli nowo utworzona sytuacja już należy do tego zbioru, nie zmienia się go. Do powstawania nowych sytuacji prowadzą trzy rodzaje działań:
- wczytywanie (ang. scanning) oznacza zaakceptowanie przez algorytm symbolu terminalnego zgodnego z oczekiwaniami analizatora zstępującego: jeśli istnieje sytuacja [A →h α •i tiη], w której bezpośrednio za kropką występuje bieżący symbol terminalny, to dodaj do zbioru sytuację [A →h αti •i+1 η] z kropką przesuniętą za ten symbol i indeksem nierozpatrzonego symbolu terminalnego zwiększonym o 1;
- przewidywanie (ang. prediction) tworzy sytuacje, odpowiadające dalszym oczekiwaniom analizatora zstępującego: jeśli istnieje sytuacja [A →h α •i Bη], w której bezpośrednio za kropką występuje symbol nieterminalny B, to dla każdej produkcji B → β dodaj do zbioru sytuację [B →i •i β], która przygotowuje algorytm na ewentualne rozpoznanie tej produkcji poczynając od najbliższego nierozpatrzonego symbolu terminalnego;
- uzupełnianie (ang. completion) stanowi wstępujący komponent algorytmu: jeśli istnieje sytuacja [A →h α •i], czyli rozpoznano całą produkcję A → α, to dla każdej sytuacji [B →g β •h Aγ], w której oczekiwano symbolu nieterminalnego A tam, gdzie zaczyna się rozpoznana produkcja A → α, dodaj do zbioru sytuację [B →g βA •i γ] z kropką przesuniętą za symbol A i uaktualnionym indeksem nierozpatrzonego symbolu terminalnego.
Wyprowadzenie wejściowego ciągu symboli terminalnych t0, … , tn−1 z symbolu startowego danej gramatyki istnieje wtedy i tylko wtedy, gdy algorytm utworzył sytuację Earleya [S’ →0 S •n].
Przykład
Dla „pikogramatyki” języka angielskiego
- S → NP VP
- NP → Det N
- NP → Det Adj N
- VP → V
- VP → V NP
i wejściowego ciągu symboli TheDet blackAdj catN ateV aDet whiteAdj mouseN algorytm tworzy następujący zbiór sytuacji Earleya:


Sytuacja Earleya Powód dodania do zbioru sytuacji [S’ →0 •0 S] inicjalizacja [S →0 •0 NP VP] przewidziano S w sytuacji [S’ →0 •0 S] [NP →0 •0 Det N] przewidziano NP w sytuacji [S →0 •0 NP VP] [NP →0 •0 Det Adj N] przewidziano NP w sytuacji [S →0 •0 NP VP] [NP →0 Det •1 N] wczytano Det w sytuacji [NP →0 •0 Det N] [NP →0 Det •1 Adj N] wczytano Det w sytuacji [NP →0 •0 Det Adj N] [NP →0 Det Adj •2 N] wczytano Adj w sytuacji [NP →0 Det •1 Adj N] [NP →0 Det Adj N •3] wczytano N w sytuacji [NP →0 Det Adj •2 N] [S →0 NP •3 VP] uzupełniono NP w sytuacji [S →0 •0 NP VP] [VP →3 •3 V] przewidziano VP w sytuacji [S →0 NP •3 VP] [VP →3 •3 V NP] przewidziano VP w sytuacji [S →0 NP •3 VP] [VP →3 V •4] wczytano V w sytuacji [VP →3 •3 V] [VP →3 V •4 NP] wczytano V w sytuacji [VP →3 •3 V NP] [S →0 NP VP •4] uzupełniono VP w sytuacji [S →0 NP •3 VP] [NP →4 •4 Det N] przewidziano NP w sytuacji [VP →3 V •4 NP] [NP →4 •4 Det Adj N] przewidziano NP w sytuacji [VP →3 V •4 NP] [S’ →0 S •4] uzupełniono S w sytuacji [S’ →0 •0 S] [NP →4 Det •5 N] wczytano Det w sytuacji [NP →4 •4 Det N] [NP →4 Det •5 Adj N] wczytano Det w sytuacji [NP →4 •4 Det Adj N] [NP →4 Det Adj •6 N] wczytano Adj w sytuacji [NP →4 Det •5 Adj N] [NP →4 Det Adj N •7] wczytano N w sytuacji [NP →4 Det Adj •6 N] [VP →3 V NP •7] uzupełniono NP w sytuacji [VP →3 V •4 NP] [S →0 NP VP •7] uzupełniono VP w sytuacji [S →0 NP •3 VP] [S’ →0 S •7] uzupełniono S w sytuacji [S’ →0 •0 S]
Ostatnia sytuacja Earleya [S’ →0 S •7] odpowiada pełnemu rozbiorowi wszystkich siedmiu symboli ciągu wejściowego. Sytuacja Earleya [S’ →0 S •4] oznacza, że pierwsze cztery symbole tego ciągu również tworzą poprawne zdanie w danej gramatyce.
Złożoność obliczeniowa
W implementacjach algorytmu Earleya zamiast jednego zbioru sytuacji korzysta się z listy zbiorów i pomija wewnątrz sytuacji indeks nierozpatrzonego symbolu wejściowego. W i-tym zbiorze przechowuje się sytuacje postaci [A →h α • η]. Spotyka się też notację [A → α • η, h] i inne. Algorytm przegląda wówczas po kolei zbiory z tej listy, dzięki czemu przyrostowo bada symbole wejściowe ti w kolejności rosnących indeksów i.
Wewnątrz zbiorów sytuacje Earleya przegląda się zazwyczaj w kolejności ich dodawania, każdą jeden raz. Wymaga to jednak modyfikacji algorytmu, jeśli ma on poprawnie działać dla gramatyk zawierających produkcje z pustą prawą stroną, o czym poniżej. Aby wydajnie przeglądać sytuacje jednego zbioru, powinny one tworzyć kolejkę, aby zaś przy próbie dodania sytuacji do kolejki wydajnie sprawdzać, czy kolejka już ją zawiera, sytuacje z każdej kolejki powinny dodatkowo należeć do tablicy asocjacyjnej. Wydajne uzupełnianie sytuacji, w których kropka nie leży na końcu produkcji, wymaga jeszcze jednej tablicy asocjacyjnej, przechowującej jako wartości listy takich sytuacji, a jako klucze – pary (Ap, i), złożone z symbolu leżącego w tych sytuacjach bezpośrednio za kropką i z indeksu nierozpatrzonego symbolu terminalnego. Ponadto, by wydajnie przewidywać nowe sytuacje, z każdym symbolem nieterminalnym powinno się związać listę wszystkich produkcji, po których lewej stronie stoi ten symbol.
Jeśli jako wymienione powyżej tablice asocjacyjne zastosować tablice mieszające, to krok polegający na tworzeniu nowej sytuacji Earleya i próbie poszerzenia o nią zbioru sytuacji można wykonać w oczekiwanym czasie O(1).
Earley wskazał w swoim artykule[6], że w ogólnym przypadku:
- i-ty zbiór liczy O(i) sytuacji, bo ograniczenie górne ich liczby równa się iloczynowi liczby możliwych wartości indeksu h (zależnej od i) oraz liczby produkcji i liczby możliwych położeń kropek w ich prawych stronach (dwa ostatnie czynniki nie przekraczają stałych zależnych od danej gramatyki, ale niezależnych od i);
- działania wczytywania i przewidywania wykonują O(1) kroków na sytuację Earleya w dowolnym zbiorze, zatem w i-tym zbiorze sytuacji wykonują O(i) kroków;
- działanie uzupełniania wykonuje O(i) kroków na każdą przetwarzaną sytuację, bo w najgorszym przypadku musi dodać O(h) sytuacji należących do h-tego zbioru, a h = O(i), zatem w i-tym zbiorze sytuacji wykonuje O(i2) kroków;
- sumowanie od i równego 0 do n daje O(n3) kroków działania algorytmu i O(n2) sytuacji.
W tym samym artykule wykazano również, że dla gramatyk jednoznacznych działanie uzupełniania wykonuje w i-tym zbiorze sytuacji O(i) kroków, co owocuje kwadratową złożonością algorytmu, oraz że klasa gramatyk, dla których algorytm Earleya działa w czasie liniowym, obejmuje gramatyki, dla których liczbę sytuacji w każdym zbiorze ogranicza z góry pewna stała. Do tej klasy należą prawie wszystkie gramatyki LR(k), oprócz niektórych gramatyk prawostronnie rekursywnych, więc także gramatyki większości języków programowania.
Algorytm Earleya działa szczególnie wydajnie z gramatykami o produkcjach lewostronnie rekursywnych. Jako przykład posłuży gramatyka
- S → Sa
- S → a
użyta do analizy ciągu aaa. Algorytm Earleya tworzy wówczas następujące sytuacje:

Sytuacja Earleya Powód dodania do zbioru sytuacji [S’ →0 •0 S] inicjalizacja [S →0 •0 Sa] przewidziano S w sytuacji [S’ →0 •0 S], a potem w sytuacji [S →0 •0 Sa] [S →0 •0 a] przewidziano S w sytuacji [S’ →0 •0 S], a potem w sytuacji [S →0 •0 Sa] [S →0 a •1] wczytano a w sytuacji [S →0 •0 a] [S’ →0 S •1] uzupełniono S w sytuacji [S’ →0 •0 S] [S →0 S •1 a] uzupełniono S w sytuacji [S →0 •0 Sa] [S →0 Sa •2] wczytano a w sytuacji [S →0 S •1 a] [S’ →0 S •2] uzupełniono S w sytuacji [S’ →0 •0 S] [S →0 S •2 a] uzupełniono S w sytuacji [S →0 •0 Sa] [S →0 Sa •3] wczytano a w sytuacji [0S → S •2 a] [S’ →0 S •3] uzupełniono S w sytuacji [S’ →0 •0 S] [S →0 S •3 a] uzupełniono S w sytuacji [S →0 •0 Sa]
Liczba sytuacji z każdą wartością indeksu przy kropce wynosi 3, więc algorytm działa w czasie liniowym.
Dla porównania użycie do analizy tego samego ciągu aaa gramatyki prawostronnie rekursywnej
- S → aS
- S → a
powoduje powstanie następujących sytuacji Earleya:

Sytuacja Earleya Powód dodania do zbioru sytuacji [S’ →0 •0 S] inicjalizacja [S →0 •0 aS] przewidziano S w sytuacji [S’ →0 •0 S] [S →0 •0 a] przewidziano S w sytuacji [S’ →0 •0 S] [S →0 a •1 S] wczytano a w sytuacji [S’ →0 •0 aS] [S →0 a •1] wczytano a w sytuacji [S’ →0 •0 a] [S →1 •1 aS] przewidziano S w sytuacji [S →0 a •1 S] [S →1 •1 a] przewidziano S w sytuacji [S →0 a •1 S] [S’ →0 S •1] uzupełniono S w sytuacji [S’ →0 •0 S] [S →1 a •2 S] wczytano a w sytuacji [S’ →1 •1 aS] [S →1 a •2] wczytano a w sytuacji [S’ →1 •1 a] [S →2 •2 aS] przewidziano S w sytuacji [S →1 a •2 S] [S →2 •2 a] przewidziano S w sytuacji [S →1 a •2 S] [S →0 aS •2] uzupełniono S w sytuacji [S’ →0 a •1 S] [S’ →0 S •2] uzupełniono S w sytuacji [S’ →0 •0 S] [S →2 a •3 S] wczytano a w sytuacji [S’ →2 •2 aS] [S →2 a •3] wczytano a w sytuacji [S’ →2 •2 a] [S →3 •3 aS] przewidziano S w sytuacji [S →2 a •3 S] [S →3 •3 a] przewidziano S w sytuacji [S →2 a •3 S] [S →1 aS •3] uzupełniono S w sytuacji [S’ →1 a •2 S] [S →0 aS •3] uzupełniono S w sytuacji [S’ →0 a •1 S] [S’ →0 S •3] uzupełniono S w sytuacji [S’ →0 •0 S]
Liczba sytuacji o danej wartości indeksu przy kropce rośnie liniowo ze wzrostem tego indeksu, zatem dla tej gramatyki algorytm działa z kwadratową złożonością czasową.
Puste produkcje
Jeśli algorytm Earleya rozpatruje sytuacje z i-tego zbioru jednokrotnie, w kolejności ich dodawania, to może działać niepoprawnie dla gramatyk, które zawierają produkcje o pustej prawej stronie (zwane też ε-produkcjami, bo ε tradycyjnie oznacza pusty ciąg symboli gramatyki). Przy uzupełnianiu sytuacji [E →i •i], która odpowiada pustej produkcji E → ε, trzeba przejrzeć niepełny jeszcze i-ty zbiór. Jeśli sytuacja [A →h α •i Eη] zostanie do niego dodana po uzupełnieniu sytuacji [E →i •i], to uzupełnianie nigdy nie doda sytuacji [A →h αE •i η]. Nie zostaną też dodane sytuacje bezpośrednio i pośrednio z niej wynikające. Może to spowodować odrzucenie poprawnego ciągu wejściowego, jak pokazuje poniższy przykład użycia gramatyki
- S → E A A A
- A → E
- E → ε
do analizy pustego ciągu ε. W zbiorze sytuacji Earleya na czerwono zaznaczono te sytuacje, których algorytm nie dodał do zbioru, choć powinien.

Sytuacja Earleya Powód dodania do zbioru sytuacji [S’ →0 •0 S] inicjalizacja [S →0 •0 E A A A] przewidziano S w sytuacji [S’ →0 •0 S] [E →0 •0] przewidziano E w sytuacji [S →0 •0 E A A A] [S →0 E •0 A A A] uzupełniono E w sytuacji [S →0 •0 E A A A] [A →0 •0 E] przewidziano A w sytuacji [S →0 E •0 A A A] [A →0 E •0] nie uzupełniono E w sytuacji [A →0 •0 E] [S →0 E A •0 A A] nie uzupełniono A w sytuacji [S →0 E •0 A A A] [S →0 E A A •0 A] nie uzupełniono A w sytuacji [S →0 E A •0 A A] [S →0 E A A A •0] nie uzupełniono A w sytuacji [S →0 E A A •0 A] [S’ →0 S •0] nie uzupełniono S w sytuacji [S’ →0 •0 S]
Opublikowano kilka rozwiązań tego problemu:
- A.V. Aho i J.D. Ullman[8] zalecają wielokrotne wykonywanie w pętli przewidywania i uzupełniania wszystkich sytuacji z i-tego zbioru tak długo, dopóki kolejne iteracje powiększają jego liczebność;
- Earley[6] zaproponował, by przy uzupełnianiu sytuacji zapamiętywać symbole nieterminalne, z których da się wyprowadzić ciąg pusty (ang. nullable symbols), które poznaje się po tym, że stoją po lewej stronie produkcji o prawej stronie pustej lub złożonej tylko z symboli sprowadzalnych do ciągu pustego, a przy dodawaniu do zbioru sytuacji [A →h α •i Bη], jeśli z symbolu B stojącego po kropce da się wyprowadzić ciąg pusty, dodać do zbioru także sytuację [A →h αB •i η];
- podobne rozwiązanie J. Aycocka i R.N. Horspoola[9] polega na zmianie przewidywania sytuacji na „jeśli istnieje sytuacja [A →h α •i Bη], to dla każdej produkcji B → β dodaj sytuację [B →i •i β]; jeśli z symbolu B można wyprowadzić ciąg pusty, to dodaj również sytuację [A →h αB •i η]”, przy czym zbiór symboli nieterminalnych sprowadzalnych do ciągu pustego można łatwo wyznaczyć z góry;
- każdą gramatykę, z której symbolu startowego nie da się wyprowadzić ciągu pustego, można przekształcić na równoważną gramatykę bez pustych produkcji[10].
Rozpoznawanie a analiza składniowa
Opisany powyżej algorytm tylko rozpoznaje, czy dany ciąg symboli terminalnych stanowi poprawne zdanie danej gramatyki bezkontekstowej (taki algorytm nazywa się po angielsku recognizer), ale nie buduje jego drzewa składni. Zaproponowano kilka sposobów tworzenia na jego podstawie właściwego parsera. Komplikację stanowi liczba drzew rozbioru, potencjalnie wykładnicza w stosunku do rozmiaru danych wejściowych, a dla gramatyk z cyklami nawet nieskończona. Istnieją jednak sposoby kodowania wszystkich drzew rozbioru w strukturach danych o rozmiarze wielomianowym względem długości ciągu wejściowego.
 |
 |
| Poprawne drzewa rozbioru ciągu aaa | |
 |
 |
| Niepoprawne drzewa rozbioru ciągu aaa | |
W artykule Earleya[6] podano, jak przekształcić algorytm rozpoznawania w parser przez dodanie do wystąpień symboli nieterminalnych wewnątrz prawych stron produkcji w sytuacjach Earleya zbioru wskaźników do sytuacji, które spowodowały uzupełnienie tych symboli: przy każdym uzupełnianiu, powodującym powstanie sytuacji [B →g βA •i γ], tworzy się wskaźnik od wystąpienia symbolu A w tej sytuacji do sytuacji [A →h α •i]. M. Tomita[11] podał jednak kontrprzykład: dla gramatyki
- S → S S
- S → a
i ciągu wejściowego aaa parser zaproponowany przez Earleya tworzy nie tylko poprawne drzewa rozbioru ciągu aaa, ale też niepoprawne drzewa rozbioru ciągów aa i aaaa.
Można temu zaradzić, dodając do sytuacji [B →g βA •i γ] powstałej w wyniku uzupełniania nie jeden, lecz parę wskaźników: do sytuacji [B →g β •h Aγ] oraz do sytuacji [A →h α •i]. Gdyby naiwnie skorzystać z tego pomysłu przez dodanie tej pary wskaźników do zestawu etykiet odróżniających sytuacje, to rząd czasu działania algorytmu mógłby przekroczyć n3, jak pokazuje przykład, pochodzący z artykułu M. Johnsona[12]: dla gramatyki
- S → S … S (m + 2 powtórzenia symbolu S)
- S → S S
- S → a
algorytm Earleya z tak zdefiniowanymi sytuacjami analizuje ciąg wejściowy a … a (n + 1 powtórzeń symbolu a, przy czym n > m) w czasie Ω(nm). Od W.A. Łapszyna[13] pochodzi pomysł przechowywania zbiorów takich par wskaźników jako wartości tablicy asocjacyjnej, której klucze to sytuacje Earleya, oraz algorytm budowy drzew rozbioru na podstawie grafu sytuacji połączonych tymi wskaźnikami. Wówczas złożoność czasowa samego parsera bez budowania drzew rozbioru nie przekracza rzędu n3. E. Scott[14] opublikowała natomiast algorytm, który w czasie O(n3) przetwarza graf sytuacji na taką wersję znanego z parserów GLR współdzielonego upakowanego lasu analizy (ang. shared packed parse forest), w której każdy węzeł ma najwyżej dwóch synów.
Na innej zasadzie opiera się propozycja D. Grunego i C.J.H. Jacobsa[15]: tworzenie drzew rozbioru ze zbioru sytuacji za pomocą parsera Ungera.
Podgląd symboli terminalnych
Operacja przewidywania w algorytmie Earleya może korzystać z podglądu (ang. lookahead). Działa ona wówczas następująco: „jeśli istnieje sytuacja [A →h α •i Bη], to dla każdej produkcji B → β dodaj sytuację [B →i •i β], o ile zbiór FIRST ciągu symboli β zawiera symbol terminalny ti”. Jak zwykle przy podglądzie, najwygodniej na końcu analizowanego ciągu symboli ustawić wartownika tn = $ spoza zbioru symboli terminalnych.
W oryginalnym artykule Earleya[6] zaproponowano stosowanie podglądu w operacji uzupełniania. Przy uzupełnianiu, inaczej niż przy przewidywaniu, nie da się z góry wyznaczyć zbioru dopuszczalnych następników, jeśli nie brać pod uwagę jego mniej wydajnej i ograniczonej wersji opartej na zbiorach FOLLOW. Wydajny podgląd przy uzupełnianiu polega na następujących modyfikacjach algorytmu:
- zbiór dopuszczalnych następników początkowej sytuacji [S’ →0 •0 S] ma jeden element – wartownika $;
- przy wczytywaniu nowo powstała sytuacja [A →h αti •i+1 η] dziedziczy zbiór dopuszczalnych następników swojej poprzedniczki [A →h α •i tiη];
- przy przewidywaniu sytuacji [B →i •i β] na podstawie sytuacji [A →h α •i Bη] o zbiorze dopuszczalnych następników NA dopuszczalne następniki nowo powstałej sytuacji wyznacza się jako zbiór FIRST(Bη) jeśli FIRST(Bη) nie zawiera symbolu pustego ε lub jako sumę zbiorów FIRST(Bη) ∪ NA jeśli FIRST(Bη) zawiera symbol pusty ε;
- przy uzupełnianiu sytuacji [A →h α •i] nowe sytuacje [B →g βA •i γ] dodaje się tylko wtedy, jeśli zbiór dopuszczalnych następników sytuacji [A →h α •i] zawiera i-ty symbol terminalny ti.
Można też stosować podgląd więcej niż jednego symbolu terminalnego.
Warianty algorytmu Earleya z podglądem różnej liczby symboli przy przewidywaniu i uzupełnianiu badali M. Bouckaert, A. Pirotte i M. Snelling[16]. W ich symulacjach najlepszy okazał się podgląd jednego symbolu przy przewidywaniu, który zmniejszał liczbę sytuacji o 20–50% w stosunku do wersji bez podglądu, natomiast narzut stosowania jakiegokolwiek podglądu przy uzupełnianiu przewyższał zyski z niego płynące. Wiele implementacji algorytmu Earleya wcale nie używa podglądu, dzięki czemu mogą bezpośrednio korzystać z danej gramatyki, pomijając jej wstępne przetwarzanie służące wyznaczeniu zbiorów FIRST.
Modyfikacje algorytmu
W artykule F.C.N. Pereiry i D.H.D. Warrena[17] pokazano, jak uogólnić tablicowe metody analizy składniowej na dowolne formalizmy gramatyczne oparte na unifikacji, również kontekstowe. Zapoczątkował on falę artykułów opisujących wersje algorytmu Earleya dla formalizmu unifikacji PATR-II[18], gramatyk przyłączania drzew (ang. tree adjoining grammar)[19][20], gramatyk S-atrybutywnych (ang. S-attribute grammar)[21], gramatyk hipergrafowych (ang. hypergraph grammar)[22], gramatyk sekwencyjnie indeksowanych (ang. sequentially indexed grammars)[23] itd. Technika zbiorów magicznych (ang. magic sets)[24] w dedukcyjnych bazach danych również opiera się na ideach Pereiry i Warrena.
S.L. Graham i M.A. Harrison[25] zwrócili uwagę na wspólne cechy algorytmu Earleya i algorytmu CYK i opracowali wraz z W.R. Ruzzo[26] algorytm analizy składniowej, stanowiący hybrydę tych dwóch algorytmów.
J. Aycock i N. Horspool[27][9] podali, jak skonstruować podobny do automatu LR(0) deterministyczny automat skończony, który parsuje dane wejściowe kilkukrotnie szybciej od tradycyjnych implementacji algorytmu Earleya.
A. Päseler[28] opracowała wariant algorytmu Earleya, która zamiast listy symboli terminalnych analizuje kratę słów (ang. word lattice). Kraty słów znajdują zastosowanie przy rozpoznawaniu mowy i analizie tekstów pisanych bez odstępów między wyrazami, np. w językach Dalekiego Wschodu.

A. Stolcke[29] opublikował algorytm, który zwraca najbardziej prawdopodobny rozbiór składniowy wejściowego ciągu symboli dla danej probabilistycznej gramatyki bezkontekstowej.
Wersje algorytmu Earleya, opracowane przez G. Lyona[30] i B. Langa[31], działają dla danych wejściowych o brakujących, nadmiarowych lub nieznanych fragmentach.
Kod źródłowy
W wikibooks zamieszczono kod źródłowy w Pythonie parsera Earleya bez podglądu, przetwarzającego puste produkcje według pomysłu Earleya[6] i tworzącego drzewa rozbioru zgodnie z ideą Łapszyna[13]. Program wypisuje kolejno tworzone sytuacje oraz wszystkie drzewa rozbioru ciągu wejściowego, zapisane w notacji nawiasowej.
Program ten znajduje cztery drzewa rozbioru niejednoznacznego zdania time flies like an arrow. Narysowane np. za pomocą programu phpSyntaxTree[32], drzewa te wyglądają następująco:
| muchy czasu lubią strzałę | czas leci jak strzała | mierz czas much podobnych do strzały | mierz czas much jak strzałę/jak strzała | |
 |
 |
 |
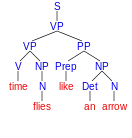 | |
| Drzewa rozbioru zdania time flies like an arrow | ||||
Przypisy
- ↑ Stephen McConnel: PC-PATR Reference Manual. 1995-10-30. [dostęp 2008-12-25]. [zarchiwizowane z tego adresu (2005-09-11)].
- ↑ Pierre Boullier, Benoît Sagot: Efficient and robust LFG parsing: SXLFG. W: Proceedings of the Ninth International Workshop on Parsing Technology. Vancouver: 2005, s. 1–10.
- ↑ John Aycock, Compiling Little Languages in Python, [w:] Proceedings of the 7th International Python Conference, Houston 1998 [zarchiwizowane z adresu 2006-07-08].
- ↑ Laurence Tratt. Domain Specific Language Implementation via Compile-Time Meta-Programming. „ACM Transactions on Programming Languages and Systems (TOPLAS)”. Październik 2008. 30(6). s. 1–40. ISSN 0164-0925.
- ↑ Jay Earley: An Efficient Context-Free Parsing Algorithm. Pittsburgh: Carnegie-Mellon University, Computer Science Department, 1968.
- 1 2 3 4 5 6 Jay Earley. An Efficient Context-Free Parsing Algorithm. „Communications of the ACM”. Luty 1970. 13(2). s. 94–102. ISSN 0001-0782. [zarchiwizowane z adresu 2005-12-10].
- ↑ Jay Earley. An Efficient Context-Free Parsing Algorithm. „Communications of the ACM”. Styczeń 1983. 26(1). s. 57–61. ISSN 0001-0782.
- ↑ Alfred V. Aho, Jeffrey D. Ullman: The Theory of Parsing, Translation, and Compiling. T. 1: Parsing. Englewood Cliffs: Prentice Hall, 1972, s. 320−332. ISBN 0-13-914556-7.
- 1 2 John Aycock, R. Nigel Horspool. Practical Earley Parsing. „The Computer Journal”. Listopad 2002. 45(6). s. 620–630. ISSN 0010-4620.
- ↑ Eliminating ε-Rules (rozdział 4.2.3.1). W: Dick Grune, Ceriel J.H. Jacobs: Parsing Techniques: A Practical Guide. New York: Springer, 2008. ISBN 0-387-20248-X.
- ↑ Masaru Tomita: An Efficient Context-Free Parsing Algorithm for Natural Languages. W: Aravind K. Joshi (red.): Proceedings of the 9th International Joint Conference on Artificial Intelligence (IJCAI-85). Los Angeles: Morgan Kaufmann, 1985, s. 756–764.
- ↑ Mark Johnson: The Computational Complexity of GLR Parsing. W: Masaru Tomita: Generalized LR Parsing. Boston/Dordrecht/London: Kluwer Academic Publishers, 1991, s. 35–42. ISBN 0-7923-9201-9.
- 1 2 Владимир А. Лапшин. Адаптированный для построения деревьев вывода алгоритм Эрли. „Научно-техническая информация. Серия 2. Информационные процессы и системы”. Maj 2005. 5. s. 1–14. ISSN 0548-0027. (ros.).
- ↑ Elizabeth Scott. SPPF-Style Parsing From Earley Recognisers. „Electronic Notes in Theoretical Computer Science”. Kwiecień 2008. 203(2). s. 53–67. ISSN 1571-0661. [zarchiwizowane z adresu 2013-05-08].
- ↑ Constructing a Parse Tree (rozdział 7.2.1.2). W: Dick Grune, Ceriel J.H. Jacobs: Parsing Techniques: A Practical Guide. New York: Springer, 2008. ISBN 0-387-20248-X.
- ↑ M. Bouckaert, Alain Pirotte, M. Snelling. Efficient Parsing Algorithms for General Context-Free Parsers. „Information Sciences”. Styczeń 1975. 8(1). s. 1–26. ISSN 0020-0255.
- ↑ Fernando C.N. Pereira, David H.D. Warren: Parsing As Deduction. W: Mitch Marcus (red.): Proceedings of the 21st Annual Meeting of the Association for Computational Linguistics. Morristown, New Jersey: Association for Computational Linguistics, 1983, s. 137–144.
- ↑ Stuart M. Shieber: Using Restriction to Extend Parsing Algorithms for Complex-Feature-Based Formalisms. W: William C. Mann (red.): Proceedings of the 23rd Annual Meeting of the Association for Computational Linguistics. Morristown, New Jersey: Association for Computational Linguistics, 1985, s. 145–152.
- ↑ Yves Schabes, Aravind K. Joshi: An Earley-Type Parsing Algorithm for Tree Adjoining Grammars. W: Jerry Hobbs (red.): Proceedings of the 26th Annual Meeting of the Association for Computational Linguistics. Morristown, New Jersey: Association for Computational Linguistics, 1988, s. 258–269.
- ↑ Yannick de Kercadio: An improved Earley parser with LTAG. W: Proceedings of the Fourth International Workshop on Tree Adjoining Grammars and Related Frameworks (TAG+). Philadelphia: University of Pennsylvania, 1998, s. 84–87.
- ↑ Nelson Correa: An Extension of Earley’s Algorithm for S-Attributed Grammars. W: Jürgen Kunze, Dorothee Reimann (red.): Proceedings of the Fifth Conference of the European Chapter of the Association for Computational Linguistics. Morristown, New Jersey: Association for Computational Linguistics, 1991, s. 299–302.
- ↑ Sebastian Seifert, Ingrid Fischer. Parsing String Generating Hypergraph Grammars. „Lecture Notes in Computer Science”. 2004. 3256. s. 352–367. ISSN 0302-9743.
- ↑ Jan van Eijck. Sequentially Indexed Grammars. „Journal of Logic and Computation”. Kwiecień 2008. 18(2). s. 205–228. ISSN 0955-792X.
- ↑ François Bancilhon, David Maier, Yehoshua Sagiv, Jeffrey D. Ullman: Magic Sets and Other Strange Ways to Implement Logic Programs (Extended Abstract). W: Avi Silberschatz (red.): Proceedings of the Fifth ACM SIGACT-SIGMOD Symposium on Principles of Database Systems. New York: Association for Computing Machinery, 1986, s. 1–15.
- ↑ Susan L. Graham, Michael A. Harrison. Parsing of General Context-Free Languages. „Advances in Computers”. 1976. 14. s. 77–185. ISSN 0065-2458.
- ↑ Susan L. Graham, Michael A. Harrison, Walter R. Ruzzo. An Improved Context-Free Recognizer. „ACM Transactions on Programming Languages and Systems (TOPLAS)”. Czerwiec 1980. 2(3). s. 415–462. ISSN 0164-0925.
- ↑ John Aycock, Nigel Horspool: Directly-Executable Earley Parsing. W: Reinhard Wilhelm (red.): Proceedings of the 10th International Conference on Compiler Construction. Berlin: Springer-Verlag, 2001, s. 229–243. ISBN 3-540-41861-X.
- ↑ Annedore Päseler: Modification of Earley’s Algorithm for Speech Recognition. W: H Niemann i in. (red.): Proceedings of the NATO Advanced Study Institute on Recent Advances in Speech Understanding and Dialog Systems. Berlin, Heidelberg: Springer-Verlag, 1988, s. 465–472. ISBN 0-387-19245-X.
- ↑ Andreas Stolcke. An Efficient Probabilistic Context-Free Parsing Algorithm that Computes Prefix Probabilities. „Computational Linguistics”. Czerwiec 1995. 21(2). s. 165–201. ISSN 0891-2017.
- ↑ Gordon Lyon. Syntax-Directed Least-Errors Analysis for Context-Free Languages: A Practical Approach. „Communications of the ACM”. Styczeń 1974. 17(1). s. 3–14. ISSN 0001-0782.
- ↑ Bernard Lang: Parsing Incomplete Sentences. W: Proceedings of the 12th Conference on Computational Linguistics. Morristown, New Jersey: Association for Computational Linguistics, 1988, s. 365–371. ISBN 963-8431-56-3.
- ↑ Mei Eisenbach, André Eisenbach: phpSyntaxTree.