| Part of a series on |
| Bayesian statistics |
|---|
| Posterior = Likelihood × Prior ÷ Evidence |
| Background |
| Model building |
| Posterior approximation |
| Estimators |
| Evidence approximation |
| Model evaluation |
Variational Bayesian methods are a family of techniques for approximating intractable integrals arising in Bayesian inference and machine learning. They are typically used in complex statistical models consisting of observed variables (usually termed "data") as well as unknown parameters and latent variables, with various sorts of relationships among the three types of random variables, as might be described by a graphical model. As typical in Bayesian inference, the parameters and latent variables are grouped together as "unobserved variables". Variational Bayesian methods are primarily used for two purposes:
- To provide an analytical approximation to the posterior probability of the unobserved variables, in order to do statistical inference over these variables.
- To derive a lower bound for the marginal likelihood (sometimes called the evidence) of the observed data (i.e. the marginal probability of the data given the model, with marginalization performed over unobserved variables). This is typically used for performing model selection, the general idea being that a higher marginal likelihood for a given model indicates a better fit of the data by that model and hence a greater probability that the model in question was the one that generated the data. (See also the Bayes factor article.)
In the former purpose (that of approximating a posterior probability), variational Bayes is an alternative to Monte Carlo sampling methods—particularly, Markov chain Monte Carlo methods such as Gibbs sampling—for taking a fully Bayesian approach to statistical inference over complex distributions that are difficult to evaluate directly or sample. In particular, whereas Monte Carlo techniques provide a numerical approximation to the exact posterior using a set of samples, variational Bayes provides a locally-optimal, exact analytical solution to an approximation of the posterior.
Variational Bayes can be seen as an extension of the expectation-maximization (EM) algorithm from maximum a posteriori estimation (MAP estimation) of the single most probable value of each parameter to fully Bayesian estimation which computes (an approximation to) the entire posterior distribution of the parameters and latent variables. As in EM, it finds a set of optimal parameter values, and it has the same alternating structure as does EM, based on a set of interlocked (mutually dependent) equations that cannot be solved analytically.
For many applications, variational Bayes produces solutions of comparable accuracy to Gibbs sampling at greater speed. However, deriving the set of equations used to update the parameters iteratively often requires a large amount of work compared with deriving the comparable Gibbs sampling equations. This is the case even for many models that are conceptually quite simple, as is demonstrated below in the case of a basic non-hierarchical model with only two parameters and no latent variables.
Mathematical derivation
Problem
In variational inference, the posterior distribution over a set of unobserved variables given some data is approximated by a so-called variational distribution,




The distribution is restricted to belong to a family of distributions of simpler form than (e.g. a family of Gaussian distributions), selected with the intention of making similar to the true posterior, .


The similarity (or dissimilarity) is measured in terms of a dissimilarity function and hence inference is performed by selecting the distribution that minimizes .

KL divergence
The most common type of variational Bayes uses the Kullback–Leibler divergence (KL-divergence) of Q from P as the choice of dissimilarity function. This choice makes this minimization tractable. The KL-divergence is defined as

Note that Q and P are reversed from what one might expect. This use of reversed KL-divergence is conceptually similar to the expectation-maximization algorithm. (Using the KL-divergence in the other way produces the expectation propagation algorithm.)
Intractability
Variational techniques are typically used to form an approximation for:

The marginalization over to calculate in the denominator is typically intractable, because, for example, the search space of is combinatorially large. Therefore, we seek an approximation, using .



Evidence lower bound
Given that , the KL-divergence above can also be written as

![{\displaystyle D_{\mathrm {KL} }(Q\parallel P)=\sum _{\mathbf {Z} }Q(\mathbf {Z} )\left[\log {\frac {Q(\mathbf {Z} )}{P(\mathbf {Z} ,\mathbf {X} )}}+\log P(\mathbf {X} )\right]=\sum _{\mathbf {Z} }Q(\mathbf {Z} )\left[\log Q(\mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]+\sum _{\mathbf {Z} }Q(\mathbf {Z} )\left[\log P(\mathbf {X} )\right]}](../I/70488fe9b787af7d32d3cbaa97479e414601db46.svg)
Because is a constant with respect to and because is a distribution, we have

![{\displaystyle D_{\mathrm {KL} }(Q\parallel P)=\sum _{\mathbf {Z} }Q(\mathbf {Z} )\left[\log Q(\mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]+\log P(\mathbf {X} )}](../I/fe7ea8e2d866fa0a91aaab65b66646a27ee2c1ef.svg)
which, according to the definition of expected value (for a discrete random variable), can be written as follows
![{\displaystyle D_{\mathrm {KL} }(Q\parallel P)=\mathbb {E} _{\mathbf {Q} }\left[\log Q(\mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]+\log P(\mathbf {X} )}](../I/a8cdf19ada48df35350f6069e8bdb467ea90fa3a.svg)
which can be rearranged to become
![{\displaystyle \log P(\mathbf {X} )=D_{\mathrm {KL} }(Q\parallel P)-\mathbb {E} _{\mathbf {Q} }\left[\log Q(\mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]=D_{\mathrm {KL} }(Q\parallel P)+{\mathcal {L}}(Q)}](../I/014dc584197ed29d710ec90a734d0979fab476e5.svg)
As the log-evidence is fixed with respect to , maximizing the final term minimizes the KL divergence of from . By appropriate choice of , becomes tractable to compute and to maximize. Hence we have both an analytical approximation for the posterior , and a lower bound for the log-evidence (since the KL-divergence is non-negative).




The lower bound is known as the (negative) variational free energy in analogy with thermodynamic free energy because it can also be expressed as a negative energy plus the entropy of . The term is also known as Evidence Lower Bound, abbreviated as ELBO, to emphasize that it is a lower bound on the log-evidence of the data.
![\operatorname {E}_{{Q}}[\log P({\mathbf {Z}},{\mathbf {X}})]](../I/a7e43c3758a771143c7934709ad3198bf43e1ca6.svg)
Proofs
By the generalized Pythagorean theorem of Bregman divergence, of which KL-divergence is a special case, it can be shown that:[1][2]


where is a convex set and the equality holds if:


In this case, the global minimizer with can be found as follows:[1]



in which the normalizing constant is:

The term is often called the evidence lower bound (ELBO) in practice, since ,[1] as shown above.


By interchanging the roles of and we can iteratively compute the approximated and of the true model's marginals and respectively. Although this iterative scheme is guaranteed to converge monotonically,[1] the converged is only a local minimizer of .








If the constrained space is confined within independent space, i.e. the above iterative scheme will become the so-called mean field approximation as shown below.


Mean field approximation
The variational distribution is usually assumed to factorize over some partition of the latent variables, i.e. for some partition of the latent variables into ,


It can be shown using the calculus of variations (hence the name "variational Bayes") that the "best" distribution for each of the factors (in terms of the distribution minimizing the KL divergence, as described above) satisfies:[3]


![{\displaystyle q_{j}^{*}(\mathbf {Z} _{j}\mid \mathbf {X} )={\frac {e^{\operatorname {E} _{q_{-j}^{*}}[\ln p(\mathbf {Z} ,\mathbf {X} )]}}{\int e^{\operatorname {E} _{q_{-j}^{*}}[\ln p(\mathbf {Z} ,\mathbf {X} )]}\,d\mathbf {Z} _{j}}}}](../I/c433a20d83c8b317b21d3ebe5f6bdc820f564310.svg)
where is the expectation of the logarithm of the joint probability of the data and latent variables, taken with respect to over all variables not in the partition: refer to Lemma 4.1 of[4] for a derivation of the distribution .
![{\displaystyle \operatorname {E} _{q_{-j}^{*}}[\ln p(\mathbf {Z} ,\mathbf {X} )]}](../I/8d25b04c50785b1ac3d66bd7e1610b77bc64314d.svg)


In practice, we usually work in terms of logarithms, i.e.:
![{\displaystyle \ln q_{j}^{*}(\mathbf {Z} _{j}\mid \mathbf {X} )=\operatorname {E} _{q_{-j}^{*}}[\ln p(\mathbf {Z} ,\mathbf {X} )]+{\text{constant}}}](../I/87a270648b59bbf964ca39d81d20b7de87d50d25.svg)
The constant in the above expression is related to the normalizing constant (the denominator in the expression above for ) and is usually reinstated by inspection, as the rest of the expression can usually be recognized as being a known type of distribution (e.g. Gaussian, gamma, etc.).
Using the properties of expectations, the expression can usually be simplified into a function of the fixed hyperparameters of the prior distributions over the latent variables and of expectations (and sometimes higher moments such as the variance) of latent variables not in the current partition (i.e. latent variables not included in ). This creates circular dependencies between the parameters of the distributions over variables in one partition and the expectations of variables in the other partitions. This naturally suggests an iterative algorithm, much like EM (the expectation-maximization algorithm), in which the expectations (and possibly higher moments) of the latent variables are initialized in some fashion (perhaps randomly), and then the parameters of each distribution are computed in turn using the current values of the expectations, after which the expectation of the newly computed distribution is set appropriately according to the computed parameters. An algorithm of this sort is guaranteed to converge.[5]

In other words, for each of the partitions of variables, by simplifying the expression for the distribution over the partition's variables and examining the distribution's functional dependency on the variables in question, the family of the distribution can usually be determined (which in turn determines the value of the constant). The formula for the distribution's parameters will be expressed in terms of the prior distributions' hyperparameters (which are known constants), but also in terms of expectations of functions of variables in other partitions. Usually these expectations can be simplified into functions of expectations of the variables themselves (i.e. the means); sometimes expectations of squared variables (which can be related to the variance of the variables), or expectations of higher powers (i.e. higher moments) also appear. In most cases, the other variables' distributions will be from known families, and the formulas for the relevant expectations can be looked up. However, those formulas depend on those distributions' parameters, which depend in turn on the expectations about other variables. The result is that the formulas for the parameters of each variable's distributions can be expressed as a series of equations with mutual, nonlinear dependencies among the variables. Usually, it is not possible to solve this system of equations directly. However, as described above, the dependencies suggest a simple iterative algorithm, which in most cases is guaranteed to converge. An example will make this process clearer.
A duality formula for variational inference
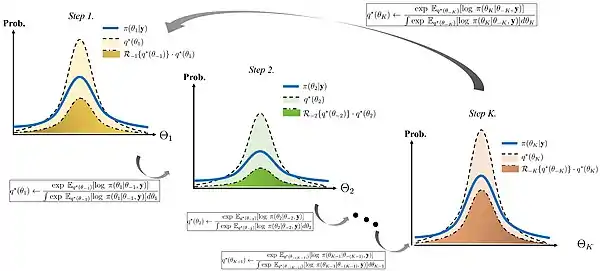
The following theorem is referred to as a duality formula for variational inference.[4] It explains some important properties of the variational distributions used in variational Bayes methods.
Theorem Consider two probability spaces and with . Assume that there is a common dominating probability measure such that and . Let denote any real-valued random variable on that satisfies . Then the following equality holds








![{\displaystyle \log E_{P}[\exp h]={\text{sup}}_{Q\ll P}\{E_{Q}[h]-D_{\text{KL}}(Q\parallel P)\}.}](../I/6b77d97ef624d72b613687f5ba1dae28f355ea34.svg)
Further, the supremum on the right-hand side is attained if and only if it holds
![{\displaystyle {\frac {q(\theta )}{p(\theta )}}={\frac {\exp h(\theta )}{E_{P}[\exp h]}},}](../I/3aa6d2bde96aa9ae886413e7889fd4496dbe710c.svg)
almost surely with respect to probability measure , where and denote the Radon-Nikodym derivatives of the probability measures and with respect to , respectively.


A basic example
Consider a simple non-hierarchical Bayesian model consisting of a set of i.i.d. observations from a Gaussian distribution, with unknown mean and variance.[6] In the following, we work through this model in great detail to illustrate the workings of the variational Bayes method.
For mathematical convenience, in the following example we work in terms of the precision — i.e. the reciprocal of the variance (or in a multivariate Gaussian, the inverse of the covariance matrix) — rather than the variance itself. (From a theoretical standpoint, precision and variance are equivalent since there is a one-to-one correspondence between the two.)
The mathematical model
We place conjugate prior distributions on the unknown mean and precision , i.e. the mean also follows a Gaussian distribution while the precision follows a gamma distribution. In other words:



The hyperparameters and in the prior distributions are fixed, given values. They can be set to small positive numbers to give broad prior distributions indicating ignorance about the prior distributions of and .


We are given data points and our goal is to infer the posterior distribution of the parameters and




The joint probability
The joint probability of all variables can be rewritten as

where the individual factors are

where

Factorized approximation
Assume that , i.e. that the posterior distribution factorizes into independent factors for and . This type of assumption underlies the variational Bayesian method. The true posterior distribution does not in fact factor this way (in fact, in this simple case, it is known to be a Gaussian-gamma distribution), and hence the result we obtain will be an approximation.

Derivation of q(μ)
Then
![{\displaystyle {\begin{aligned}\ln q_{\mu }^{*}(\mu )&=\operatorname {E} _{\tau }\left[\ln p(\mathbf {X} \mid \mu ,\tau )+\ln p(\mu \mid \tau )+\ln p(\tau )\right]+C\\&=\operatorname {E} _{\tau }\left[\ln p(\mathbf {X} \mid \mu ,\tau )\right]+\operatorname {E} _{\tau }\left[\ln p(\mu \mid \tau )\right]+\operatorname {E} _{\tau }\left[\ln p(\tau )\right]+C\\&=\operatorname {E} _{\tau }\left[\ln \prod _{n=1}^{N}{\mathcal {N}}\left(x_{n}\mid \mu ,\tau ^{-1}\right)\right]+\operatorname {E} _{\tau }\left[\ln {\mathcal {N}}\left(\mu \mid \mu _{0},(\lambda _{0}\tau )^{-1}\right)\right]+C_{2}\\&=\operatorname {E} _{\tau }\left[\ln \prod _{n=1}^{N}{\sqrt {\frac {\tau }{2\pi }}}e^{-{\frac {(x_{n}-\mu )^{2}\tau }{2}}}\right]+\operatorname {E} _{\tau }\left[\ln {\sqrt {\frac {\lambda _{0}\tau }{2\pi }}}e^{-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}}\right]+C_{2}\\&=\operatorname {E} _{\tau }\left[\sum _{n=1}^{N}\left({\frac {1}{2}}(\ln \tau -\ln 2\pi )-{\frac {(x_{n}-\mu )^{2}\tau }{2}}\right)\right]+\operatorname {E} _{\tau }\left[{\frac {1}{2}}(\ln \lambda _{0}+\ln \tau -\ln 2\pi )-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}\right]+C_{2}\\&=\operatorname {E} _{\tau }\left[\sum _{n=1}^{N}-{\frac {(x_{n}-\mu )^{2}\tau }{2}}\right]+\operatorname {E} _{\tau }\left[-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}\right]+\operatorname {E} _{\tau }\left[\sum _{n=1}^{N}{\frac {1}{2}}(\ln \tau -\ln 2\pi )\right]+\operatorname {E} _{\tau }\left[{\frac {1}{2}}(\ln \lambda _{0}+\ln \tau -\ln 2\pi )\right]+C_{2}\\&=\operatorname {E} _{\tau }\left[\sum _{n=1}^{N}-{\frac {(x_{n}-\mu )^{2}\tau }{2}}\right]+\operatorname {E} _{\tau }\left[-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}\right]+C_{3}\\&=-{\frac {\operatorname {E} _{\tau }[\tau ]}{2}}\left\{\sum _{n=1}^{N}(x_{n}-\mu )^{2}+\lambda _{0}(\mu -\mu _{0})^{2}\right\}+C_{3}\end{aligned}}}](../I/c64dbf7b78ed109532c4258d2f03ed35181be164.svg)
In the above derivation, , and refer to values that are constant with respect to . Note that the term is not a function of and will have the same value regardless of the value of . Hence in line 3 we can absorb it into the constant term at the end. We do the same thing in line 7.



![\operatorname {E}_{{\tau }}[\ln p(\tau )]](../I/ccf212e8b1c0bdaf7c00735ff771c5f117572089.svg)
The last line is simply a quadratic polynomial in . Since this is the logarithm of , we can see that itself is a Gaussian distribution.

With a certain amount of tedious math (expanding the squares inside of the braces, separating out and grouping the terms involving and and completing the square over ), we can derive the parameters of the Gaussian distribution:

![\begin{align}
\ln q_\mu^*(\mu) &= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ \sum_{n=1}^N (x_n-\mu)^2 + \lambda_0(\mu-\mu_0)^2 \right\} + C_3 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ \sum_{n=1}^N (x_n^2-2x_n\mu + \mu^2) + \lambda_0(\mu^2-2\mu_0\mu + \mu_0^2) \right \} + C_3 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ \left(\sum_{n=1}^N x_n^2\right)-2\left(\sum_{n=1}^N x_n\right)\mu + \left ( \sum_{n=1}^N \mu^2 \right) + \lambda_0\mu^2-2\lambda_0\mu_0\mu + \lambda_0\mu_0^2 \right\} + C_3 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\mu^2 -2\left(\lambda_0\mu_0 + \sum_{n=1}^N x_n\right)\mu + \left(\sum_{n=1}^N x_n^2\right) + \lambda_0\mu_0^2 \right\} + C_3 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\mu^2 -2\left(\lambda_0\mu_0 + \sum_{n=1}^N x_n\right)\mu \right\} + C_4 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N} \right)(\lambda_0+N) \mu \right\} + C_4 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu\right) \right\} + C_4 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu + \left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 - \left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2\right) \right\} + C_4 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu + \left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 \right) \right\} + C_5 \\
&= -\frac{\operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu-\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 \right\} + C_5 \\
&= -\frac{1}{2} (\lambda_0+N)\operatorname{E}_{\tau}[\tau] \left(\mu-\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 + C_5
\end{align}](../I/b95121a849ebbf25ba5413565ef4696267ba0e42.svg)
Note that all of the above steps can be shortened by using the formula for the sum of two quadratics.
In other words:
![{\displaystyle {\begin{aligned}q_{\mu }^{*}(\mu )&\sim {\mathcal {N}}(\mu \mid \mu _{N},\lambda _{N}^{-1})\\\mu _{N}&={\frac {\lambda _{0}\mu _{0}+N{\bar {x}}}{\lambda _{0}+N}}\\\lambda _{N}&=(\lambda _{0}+N)\operatorname {E} _{\tau }[\tau ]\\{\bar {x}}&={\frac {1}{N}}\sum _{n=1}^{N}x_{n}\end{aligned}}}](../I/2d299b83cbb420dff824c2914458942a0fb39859.svg)
Derivation of q(τ)
The derivation of is similar to above, although we omit some of the details for the sake of brevity.

![\begin{align}
\ln q_\tau^*(\tau) &= \operatorname{E}_{\mu}[\ln p(\mathbf{X}\mid \mu,\tau) + \ln p(\mu\mid \tau)] + \ln p(\tau) + \text{constant} \\
&= (a_0 - 1) \ln \tau - b_0 \tau + \frac{1}{2} \ln \tau + \frac{N}{2} \ln \tau - \frac{\tau}{2} \operatorname{E}_\mu \left [ \sum_{n=1}^N (x_n-\mu)^2 + \lambda_0(\mu - \mu_0)^2 \right ] + \text{constant}
\end{align}](../I/58986c8046658988c363da1009d0beedc83ce01c.svg)
Exponentiating both sides, we can see that is a gamma distribution. Specifically:
![{\begin{aligned}q_{\tau }^{*}(\tau )&\sim \operatorname {Gamma}(\tau \mid a_{N},b_{N})\\a_{N}&=a_{0}+{\frac {N+1}{2}}\\b_{N}&=b_{0}+{\frac {1}{2}}\operatorname {E}_{\mu }\left[\sum _{{n=1}}^{N}(x_{n}-\mu )^{2}+\lambda _{0}(\mu -\mu _{0})^{2}\right]\end{aligned}}](../I/f6ca127beab48a5d09ca7e57f8826ed863d01727.svg)
Algorithm for computing the parameters
Let us recap the conclusions from the previous sections:
and
In each case, the parameters for the distribution over one of the variables depend on expectations taken with respect to the other variable. We can expand the expectations, using the standard formulas for the expectations of moments of the Gaussian and gamma distributions:
![\begin{align}
\operatorname{E}[\tau\mid a_N, b_N] &= \frac{a_N}{b_N} \\
\operatorname{E} \left [\mu\mid\mu_N,\lambda_N^{-1} \right ] &= \mu_N \\
\operatorname{E}\left[X^2 \right] &= \operatorname{Var}(X) + (\operatorname{E}[X])^2 \\
\operatorname{E} \left [\mu^2\mid\mu_N,\lambda_N^{-1} \right ] &= \lambda_N^{-1} + \mu_N^2
\end{align}](../I/917241f915e88f88f8e3ff74096507c6efe8551c.svg)
Applying these formulas to the above equations is trivial in most cases, but the equation for takes more work:

![\begin{align}
b_N &= b_0 + \frac{1}{2} \operatorname{E}_\mu \left[\sum_{n=1}^N (x_n-\mu)^2 + \lambda_0(\mu - \mu_0)^2\right] \\
&= b_0 + \frac{1}{2} \operatorname{E}_\mu \left[ (\lambda_0+N)\mu^2 -2 \left (\lambda_0\mu_0 + \sum_{n=1}^N x_n \right )\mu + \left(\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right] \\
&= b_0 + \frac{1}{2} \left[ (\lambda_0+N)\operatorname{E}_\mu[\mu^2] -2 \left (\lambda_0\mu_0 + \sum_{n=1}^N x_n \right)\operatorname{E}_\mu [\mu] + \left (\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right] \\
&= b_0 + \frac{1}{2} \left[ (\lambda_0+N) \left (\lambda_N^{-1} + \mu_N^2 \right ) -2 \left (\lambda_0\mu_0 + \sum_{n=1}^N x_n \right)\mu_N + \left(\sum_{n=1}^N x_n^2 \right) + \lambda_0\mu_0^2 \right] \\
\end{align}](../I/16171a58ee7ad1a9dca35de3637f8034197b22a6.svg)
We can then write the parameter equations as follows, without any expectations:
![\begin{align}
\mu_N &= \frac{\lambda_0 \mu_0 + N \bar{x}}{\lambda_0 + N} \\
\lambda_N &= (\lambda_0 + N) \frac{a_N}{b_N} \\
\bar{x} &= \frac{1}{N}\sum_{n=1}^N x_n \\
a_N &= a_0 + \frac{N+1}{2} \\
b_N &= b_0 + \frac{1}{2} \left[ (\lambda_0+N) \left (\lambda_N^{-1} + \mu_N^2 \right ) -2 \left (\lambda_0\mu_0 + \sum_{n=1}^N x_n \right )\mu_N + \left (\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right]
\end{align}](../I/fe12241932dc8dfb6a202e043b02cd60b3f593a6.svg)
Note that there are circular dependencies among the formulas for and . This naturally suggests an EM-like algorithm:

- Compute and Use these values to compute and
- Initialize to some arbitrary value.
- Use the current value of along with the known values of the other parameters, to compute .
- Use the current value of along with the known values of the other parameters, to compute .
- Repeat the last two steps until convergence (i.e. until neither value has changed more than some small amount).






We then have values for the hyperparameters of the approximating distributions of the posterior parameters, which we can use to compute any properties we want of the posterior — e.g. its mean and variance, a 95% highest-density region (the smallest interval that includes 95% of the total probability), etc.
It can be shown that this algorithm is guaranteed to converge to a local maximum.
Note also that the posterior distributions have the same form as the corresponding prior distributions. We did not assume this; the only assumption we made was that the distributions factorize, and the form of the distributions followed naturally. It turns out (see below) that the fact that the posterior distributions have the same form as the prior distributions is not a coincidence, but a general result whenever the prior distributions are members of the exponential family, which is the case for most of the standard distributions.
Further discussion
Step-by-step recipe
The above example shows the method by which the variational-Bayesian approximation to a posterior probability density in a given Bayesian network is derived:
- Describe the network with a graphical model, identifying the observed variables (data) and unobserved variables (parameters and latent variables ) and their conditional probability distributions. Variational Bayes will then construct an approximation to the posterior probability . The approximation has the basic property that it is a factorized distribution, i.e. a product of two or more independent distributions over disjoint subsets of the unobserved variables.
- Partition the unobserved variables into two or more subsets, over which the independent factors will be derived. There is no universal procedure for doing this; creating too many subsets yields a poor approximation, while creating too few makes the entire variational Bayes procedure intractable. Typically, the first split is to separate the parameters and latent variables; often, this is enough by itself to produce a tractable result. Assume that the partitions are called .
- For a given partition , write down the formula for the best approximating distribution using the basic equation .
- Fill in the formula for the joint probability distribution using the graphical model. Any component conditional distributions that don't involve any of the variables in can be ignored; they will be folded into the constant term.
- Simplify the formula and apply the expectation operator, following the above example. Ideally, this should simplify into expectations of basic functions of variables not in (e.g. first or second raw moments, expectation of a logarithm, etc.). In order for the variational Bayes procedure to work well, these expectations should generally be expressible analytically as functions of the parameters and/or hyperparameters of the distributions of these variables. In all cases, these expectation terms are constants with respect to the variables in the current partition.
- The functional form of the formula with respect to the variables in the current partition indicates the type of distribution. In particular, exponentiating the formula generates the probability density function (PDF) of the distribution (or at least, something proportional to it, with unknown normalization constant). In order for the overall method to be tractable, it should be possible to recognize the functional form as belonging to a known distribution. Significant mathematical manipulation may be required to convert the formula into a form that matches the PDF of a known distribution. When this can be done, the normalization constant can be reinstated by definition, and equations for the parameters of the known distribution can be derived by extracting the appropriate parts of the formula.
- When all expectations can be replaced analytically with functions of variables not in the current partition, and the PDF put into a form that allows identification with a known distribution, the result is a set of equations expressing the values of the optimum parameters as functions of the parameters of variables in other partitions.
- When this procedure can be applied to all partitions, the result is a set of mutually linked equations specifying the optimum values of all parameters.
- An expectation maximization (EM) type procedure is then applied, picking an initial value for each parameter and the iterating through a series of steps, where at each step we cycle through the equations, updating each parameter in turn. This is guaranteed to converge.



![\ln q_{j}^{{*}}({\mathbf {Z}}_{j}\mid {\mathbf {X}})=\operatorname {E}_{{i\neq j}}[\ln p({\mathbf {Z}},{\mathbf {X}})]+{\text{constant}}](../I/931ba9fd5d59d6d74dad8cf2a82448fbca0c5ff9.svg)
Most important points
Due to all of the mathematical manipulations involved, it is easy to lose track of the big picture. The important things are:
- The idea of variational Bayes is to construct an analytical approximation to the posterior probability of the set of unobserved variables (parameters and latent variables), given the data. This means that the form of the solution is similar to other Bayesian inference methods, such as Gibbs sampling — i.e. a distribution that seeks to describe everything that is known about the variables. As in other Bayesian methods — but unlike e.g. in expectation maximization (EM) or other maximum likelihood methods — both types of unobserved variables (i.e. parameters and latent variables) are treated the same, i.e. as random variables. Estimates for the variables can then be derived in the standard Bayesian ways, e.g. calculating the mean of the distribution to get a single point estimate or deriving a credible interval, highest density region, etc.
- "Analytical approximation" means that a formula can be written down for the posterior distribution. The formula generally consists of a product of well-known probability distributions, each of which factorizes over a set of unobserved variables (i.e. it is conditionally independent of the other variables, given the observed data). This formula is not the true posterior distribution, but an approximation to it; in particular, it will generally agree fairly closely in the lowest moments of the unobserved variables, e.g. the mean and variance.
- The result of all of the mathematical manipulations is (1) the identity of the probability distributions making up the factors, and (2) mutually dependent formulas for the parameters of these distributions. The actual values of these parameters are computed numerically, through an alternating iterative procedure much like EM.
Compared with expectation maximization (EM)
Variational Bayes (VB) is often compared with expectation maximization (EM). The actual numerical procedure is quite similar, in that both are alternating iterative procedures that successively converge on optimum parameter values. The initial steps to derive the respective procedures are also vaguely similar, both starting out with formulas for probability densities and both involving significant amounts of mathematical manipulations.
However, there are a number of differences. Most important is what is being computed.
- EM computes point estimates of posterior distribution of those random variables that can be categorized as "parameters", but only estimates of the actual posterior distributions of the latent variables (at least in "soft EM", and often only when the latent variables are discrete). The point estimates computed are the modes of these parameters; no other information is available.
- VB, on the other hand, computes estimates of the actual posterior distribution of all variables, both parameters and latent variables. When point estimates need to be derived, generally the mean is used rather than the mode, as is normal in Bayesian inference. Concomitant with this, the parameters computed in VB do not have the same significance as those in EM. EM computes optimum values of the parameters of the Bayes network itself. VB computes optimum values of the parameters of the distributions used to approximate the parameters and latent variables of the Bayes network. For example, a typical Gaussian mixture model will have parameters for the mean and variance of each of the mixture components. EM would directly estimate optimum values for these parameters. VB, however, would first fit a distribution to these parameters — typically in the form of a prior distribution, e.g. a normal-scaled inverse gamma distribution — and would then compute values for the parameters of this prior distribution, i.e. essentially hyperparameters. In this case, VB would compute optimum estimates of the four parameters of the normal-scaled inverse gamma distribution that describes the joint distribution of the mean and variance of the component.
A more complex example

Imagine a Bayesian Gaussian mixture model described as follows:[7]
![{\begin{aligned}{\mathbf {\pi }}&\sim \operatorname {SymDir}(K,\alpha _{0})\\{\mathbf {\Lambda }}_{{i=1\dots K}}&\sim {\mathcal {W}}({\mathbf {W}}_{0},\nu _{0})\\{\mathbf {\mu }}_{{i=1\dots K}}&\sim {\mathcal {N}}({\mathbf {\mu }}_{0},(\beta _{0}{\mathbf {\Lambda }}_{i})^{{-1}})\\{\mathbf {z}}[i=1\dots N]&\sim \operatorname {Mult}(1,{\mathbf {\pi }})\\{\mathbf {x}}_{{i=1\dots N}}&\sim {\mathcal {N}}({\mathbf {\mu }}_{{z_{i}}},{{\mathbf {\Lambda }}_{{z_{i}}}}^{{-1}})\\K&={\text{number of mixing components}}\\N&={\text{number of data points}}\end{aligned}}](../I/6e54f90a522209bd5e80751661fbd8f25570b952.svg)
Note:
- SymDir() is the symmetric Dirichlet distribution of dimension , with the hyperparameter for each component set to . The Dirichlet distribution is the conjugate prior of the categorical distribution or multinomial distribution.
- is the Wishart distribution, which is the conjugate prior of the precision matrix (inverse covariance matrix) for a multivariate Gaussian distribution.
- Mult() is a multinomial distribution over a single observation (equivalent to a categorical distribution). The state space is a "one-of-K" representation, i.e., a -dimensional vector in which one of the elements is 1 (specifying the identity of the observation) and all other elements are 0.
- is the Gaussian distribution, in this case specifically the multivariate Gaussian distribution.




The interpretation of the above variables is as follows:
- is the set of data points, each of which is a -dimensional vector distributed according to a multivariate Gaussian distribution.
- is a set of latent variables, one per data point, specifying which mixture component the corresponding data point belongs to, using a "one-of-K" vector representation with components for , as described above.
- is the mixing proportions for the mixture components.
- and specify the parameters (mean and precision) associated with each mixture component.








The joint probability of all variables can be rewritten as

where the individual factors are

where

Assume that .

Then[8]
![{\begin{aligned}\ln q^{*}({\mathbf {Z}})&=\operatorname {E}_{{{\mathbf {\pi }},{\mathbf {\mu }},{\mathbf {\Lambda }}}}[\ln p({\mathbf {X}},{\mathbf {Z}},{\mathbf {\pi }},{\mathbf {\mu }},{\mathbf {\Lambda }})]+{\text{constant}}\\&=\operatorname {E}_{{{\mathbf {\pi }}}}[\ln p({\mathbf {Z}}\mid {\mathbf {\pi }})]+\operatorname {E}_{{{\mathbf {\mu }},{\mathbf {\Lambda }}}}[\ln p({\mathbf {X}}\mid {\mathbf {Z}},{\mathbf {\mu }},{\mathbf {\Lambda }})]+{\text{constant}}\\&=\sum _{{n=1}}^{N}\sum _{{k=1}}^{K}z_{{nk}}\ln \rho _{{nk}}+{\text{constant}}\end{aligned}}](../I/a9e6956e240ed7d5d347063c687111ca758eabfd.svg)
where we have defined
![\ln \rho _{{nk}}=\operatorname {E}[\ln \pi _{k}]+{\frac {1}{2}}\operatorname {E}[\ln |{\mathbf {\Lambda }}_{k}|]-{\frac {D}{2}}\ln(2\pi )-{\frac {1}{2}}\operatorname {E}_{{{\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}}}[({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k})^{{{\rm {T}}}}{\mathbf {\Lambda }}_{k}({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k})]](../I/6ec0788f8a16fa7e700c96d3af8382f54cbb287f.svg)
Exponentiating both sides of the formula for yields


Requiring that this be normalized ends up requiring that the sum to 1 over all values of , yielding



where

In other words, is a product of single-observation multinomial distributions, and factors over each individual , which is distributed as a single-observation multinomial distribution with parameters for .



Furthermore, we note that
![\operatorname {E}[z_{{nk}}]=r_{{nk}}\,](../I/c15f150fa73aec952164769cfde73f6df58590e6.svg)
which is a standard result for categorical distributions.
Now, considering the factor , note that it automatically factors into due to the structure of the graphical model defining our Gaussian mixture model, which is specified above.


Then,
![{\begin{aligned}\ln q^{*}({\mathbf {\pi }})&=\ln p({\mathbf {\pi }})+\operatorname {E}_{{{\mathbf {Z}}}}[\ln p({\mathbf {Z}}\mid {\mathbf {\pi }})]+{\text{constant}}\\&=(\alpha _{0}-1)\sum _{{k=1}}^{K}\ln \pi _{k}+\sum _{{n=1}}^{N}\sum _{{k=1}}^{K}r_{{nk}}\ln \pi _{k}+{\text{constant}}\end{aligned}}](../I/9ce937b397d56eb7f4ee329522f5ba5379abd69f.svg)
Taking the exponential of both sides, we recognize as a Dirichlet distribution


where

where

Finally
![\ln q^{*}({\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k})=\ln p({\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k})+\sum _{{n=1}}^{N}\operatorname {E}[z_{{nk}}]\ln {\mathcal {N}}({\mathbf {x}}_{n}\mid {\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}^{{-1}})+{\text{constant}}](../I/cc21b5385915806fac7030e8de06621c21ee716c.svg)
Grouping and reading off terms involving and , the result is a Gaussian-Wishart distribution given by



given the definitions

Finally, notice that these functions require the values of , which make use of , which is defined in turn based on , , and . Now that we have determined the distributions over which these expectations are taken, we can derive formulas for them:
![\operatorname {E}[\ln \pi _{k}]](../I/7038f8179432a3693f8296feacc5f8874ba6f267.svg)
![\operatorname {E}[\ln |{\mathbf {\Lambda }}_{k}|]](../I/c07e1eecf8caee684700b0e4b63cc117051feab1.svg)
![\operatorname {E}_{{{\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}}}[({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k})^{{{\rm {T}}}}{\mathbf {\Lambda }}_{k}({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k})]](../I/632ace27969c8d456caa65b802e8e8ce268e51bb.svg)
![{\displaystyle {\begin{aligned}\operatorname {E} _{\mathbf {\mu } _{k},\mathbf {\Lambda } _{k}}[(\mathbf {x} _{n}-\mathbf {\mu } _{k})^{\rm {T}}\mathbf {\Lambda } _{k}(\mathbf {x} _{n}-\mathbf {\mu } _{k})]&=D\beta _{k}^{-1}+\nu _{k}(\mathbf {x} _{n}-\mathbf {m} _{k})^{\rm {T}}\mathbf {W} _{k}(\mathbf {x} _{n}-\mathbf {m} _{k})\\\ln {\widetilde {\Lambda }}_{k}&\equiv \operatorname {E} [\ln |\mathbf {\Lambda } _{k}|]=\sum _{i=1}^{D}\psi \left({\frac {\nu _{k}+1-i}{2}}\right)+D\ln 2+\ln |\mathbf {W} _{k}|\\\ln {\widetilde {\pi }}_{k}&\equiv \operatorname {E} \left[\ln |\pi _{k}|\right]=\psi (\alpha _{k})-\psi \left(\sum _{i=1}^{K}\alpha _{i}\right)\end{aligned}}}](../I/ef9311bd1332799fbb4578b2547cd94b56b37acd.svg)
These results lead to

These can be converted from proportional to absolute values by normalizing over so that the corresponding values sum to 1.
Note that:
- The update equations for the parameters , , and of the variables and depend on the statistics , , and , and these statistics in turn depend on .
- The update equations for the parameters of the variable depend on the statistic , which depends in turn on .
- The update equation for has a direct circular dependence on , , and as well as an indirect circular dependence on , and through and .










This suggests an iterative procedure that alternates between two steps:
- An E-step that computes the value of using the current values of all the other parameters.
- An M-step that uses the new value of to compute new values of all the other parameters.
Note that these steps correspond closely with the standard EM algorithm to derive a maximum likelihood or maximum a posteriori (MAP) solution for the parameters of a Gaussian mixture model. The responsibilities in the E step correspond closely to the posterior probabilities of the latent variables given the data, i.e. ; the computation of the statistics , , and corresponds closely to the computation of corresponding "soft-count" statistics over the data; and the use of those statistics to compute new values of the parameters corresponds closely to the use of soft counts to compute new parameter values in normal EM over a Gaussian mixture model.

Exponential-family distributions
Note that in the previous example, once the distribution over unobserved variables was assumed to factorize into distributions over the "parameters" and distributions over the "latent data", the derived "best" distribution for each variable was in the same family as the corresponding prior distribution over the variable. This is a general result that holds true for all prior distributions derived from the exponential family.
See also
- Variational message passing: a modular algorithm for variational Bayesian inference.
- Variational autoencoder: an artificial neural network belonging to the families of probabilistic graphical models and Variational Bayesian methods.
- Expectation-maximization algorithm: a related approach which corresponds to a special case of variational Bayesian inference.
- Generalized filtering: a variational filtering scheme for nonlinear state space models.
- Calculus of variations: the field of mathematical analysis that deals with maximizing or minimizing functionals.
- Maximum entropy discrimination: This is a variational inference framework that allows for introducing and accounting for additional large-margin constraints[9]
References
- 1 2 3 4 Tran, Viet Hung (2018). "Copula Variational Bayes inference via information geometry". arXiv:1803.10998 [cs.IT].
- 1 2 Adamčík, Martin (2014). "The Information Geometry of Bregman Divergences and Some Applications in Multi-Expert Reasoning". Entropy. 16 (12): 6338–6381. Bibcode:2014Entrp..16.6338A. doi:10.3390/e16126338.
- ↑ Nguyen, Duy (15 August 2023). "AN IN DEPTH INTRODUCTION TO VARIATIONAL BAYES NOTE". SSRN 4541076. Retrieved 15 August 2023.
- 1 2 3 Lee, Se Yoon (2021). "Gibbs sampler and coordinate ascent variational inference: A set-theoretical review". Communications in Statistics - Theory and Methods. 51 (6): 1–21. arXiv:2008.01006. doi:10.1080/03610926.2021.1921214. S2CID 220935477.
- ↑ Boyd, Stephen P.; Vandenberghe, Lieven (2004). Convex Optimization (PDF). Cambridge University Press. ISBN 978-0-521-83378-3. Retrieved October 15, 2011.
- ↑ Bishop, Christopher M. (2006). "Chapter 10". Pattern Recognition and Machine Learning. Springer. ISBN 978-0-387-31073-2.
- ↑ Nguyen, Duy (15 August 2023). "AN IN DEPTH INTRODUCTION TO VARIATIONAL BAYES NOTE". SSRN 4541076. Retrieved 15 August 2023.
- ↑ Nguyen, Duy (15 August 2023). "AN IN DEPTH INTRODUCTION TO VARIATIONAL BAYES NOTE". SSRN 4541076. Retrieved 15 August 2023.
- ↑ Sotirios P. Chatzis, “Infinite Markov-Switching Maximum Entropy Discrimination Machines,” Proc. 30th International Conference on Machine Learning (ICML). Journal of Machine Learning Research: Workshop and Conference Proceedings, vol. 28, no. 3, pp. 729–737, June 2013.
External links
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay provides an introduction to variational methods (p. 422).
- An in depth introduction to Variational Bayes note. Nguyen, D. 2023
- A Tutorial on Variational Bayes. Fox, C. and Roberts, S. 2012. Artificial Intelligence Review, doi:10.1007/s10462-011-9236-8.
- Variational-Bayes Repository A repository of research papers, software, and links related to the use of variational methods for approximate Bayesian learning up to 2003.
- Variational Algorithms for Approximate Bayesian Inference, by M. J. Beal includes comparisons of EM to Variational Bayesian EM and derivations of several models including Variational Bayesian HMMs.
- High-Level Explanation of Variational Inference by Jason Eisner may be worth reading before a more mathematically detailed treatment.
- Copula Variational Bayes inference via information geometry (pdf) by Tran, V.H. 2018. This paper is primarily written for students. Via Bregman divergence, the paper shows that Variational Bayes is simply a generalized Pythagorean projection of true model onto an arbitrarily correlated (copula) distributional space, of which the independent space is merely a special case.