Originally introduced by Richard E. Bellman in (Bellman 1957), stochastic dynamic programming is a technique for modelling and solving problems of decision making under uncertainty. Closely related to stochastic programming and dynamic programming, stochastic dynamic programming represents the problem under scrutiny in the form of a Bellman equation. The aim is to compute a policy prescribing how to act optimally in the face of uncertainty.
A motivating example: Gambling game
A gambler has $2, she is allowed to play a game of chance 4 times and her goal is to maximize her probability of ending up with a least $6. If the gambler bets $ on a play of the game, then with probability 0.4 she wins the game, recoup the initial bet, and she increases her capital position by $; with probability 0.6, she loses the bet amount $; all plays are pairwise independent. On any play of the game, the gambler may not bet more money than she has available at the beginning of that play.[1]

Stochastic dynamic programming can be employed to model this problem and determine a betting strategy that, for instance, maximizes the gambler's probability of attaining a wealth of at least $6 by the end of the betting horizon.
Note that if there is no limit to the number of games that can be played, the problem becomes a variant of the well known St. Petersburg paradox.



Formal background
Consider a discrete system defined on stages in which each stage is characterized by


- an initial state , where is the set of feasible states at the beginning of stage ;
- a decision variable , where is the set of feasible actions at stage – note that may be a function of the initial state ;
- an immediate cost/reward function , representing the cost/reward at stage if is the initial state and the action selected;
- a state transition function that leads the system towards state .









Let represent the optimal cost/reward obtained by following an optimal policy over stages . Without loss of generality in what follow we will consider a reward maximisation setting. In deterministic dynamic programming one usually deals with functional equations taking the following structure



where and the boundary condition of the system is

The aim is to determine the set of optimal actions that maximise . Given the current state and the current action , we know with certainty the reward secured during the current stage and – thanks to the state transition function – the future state towards which the system transitions.


In practice, however, even if we know the state of the system at the beginning of the current stage as well as the decision taken, the state of the system at the beginning of the next stage and the current period reward are often random variables that can be observed only at the end of the current stage.
Stochastic dynamic programming deals with problems in which the current period reward and/or the next period state are random, i.e. with multi-stage stochastic systems. The decision maker's goal is to maximise expected (discounted) reward over a given planning horizon.
In their most general form, stochastic dynamic programs deal with functional equations taking the following structure

where
- is the maximum expected reward that can be attained during stages , given state at the beginning of stage ;
- belongs to the set of feasible actions at stage given initial state ;
- is the discount factor;
- is the conditional probability that the state at the end of stage is given current state and selected action .




Markov decision processes represent a special class of stochastic dynamic programs in which the underlying stochastic process is a stationary process that features the Markov property.
Gambling game as a stochastic dynamic program
Gambling game can be formulated as a Stochastic Dynamic Program as follows: there are games (i.e. stages) in the planning horizon

- the state in period represents the initial wealth at the beginning of period ;
- the action given state in period is the bet amount ;
- the transition probability from state to state when action is taken in state is easily derived from the probability of winning (0.4) or losing (0.6) a game.





Let be the probability that, by the end of game 4, the gambler has at least $6, given that she has $ at the beginning of game .

- the immediate profit incurred if action is taken in state is given by the expected value .

To derive the functional equation, define as a bet that attains , then at the beginning of game


- if it is impossible to attain the goal, i.e. for ;
- if the goal is attained, i.e. for ;
- if the gambler should bet enough to attain the goal, i.e. for .






For the functional equation is , where ranges in ; the aim is to find .




Given the functional equation, an optimal betting policy can be obtained via forward recursion or backward recursion algorithms, as outlined below.
Solution methods
Stochastic dynamic programs can be solved to optimality by using backward recursion or forward recursion algorithms. Memoization is typically employed to enhance performance. However, like deterministic dynamic programming also its stochastic variant suffers from the curse of dimensionality. For this reason approximate solution methods are typically employed in practical applications.
Backward recursion
Given a bounded state space, backward recursion (Bertsekas 2000) begins by tabulating for every possible state belonging to the final stage . Once these values are tabulated, together with the associated optimal state-dependent actions , it is possible to move to stage and tabulate for all possible states belonging to the stage . The process continues by considering in a backward fashion all remaining stages up to the first one. Once this tabulation process is complete, – the value of an optimal policy given initial state – as well as the associated optimal action can be easily retrieved from the table. Since the computation proceeds in a backward fashion, it is clear that backward recursion may lead to computation of a large number of states that are not necessary for the computation of .







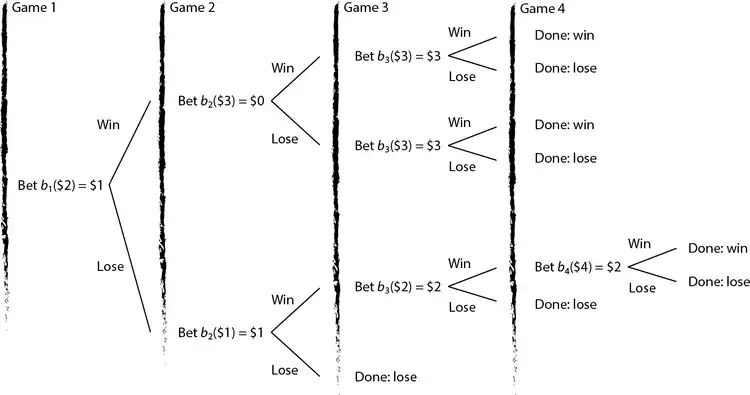
Example: Gambling game
Forward recursion
Given the initial state of the system at the beginning of period 1, forward recursion (Bertsekas 2000) computes by progressively expanding the functional equation (forward pass). This involves recursive calls for all that are necessary for computing a given . The value of an optimal policy and its structure are then retrieved via a (backward pass) in which these suspended recursive calls are resolved. A key difference from backward recursion is the fact that is computed only for states that are relevant for the computation of . Memoization is employed to avoid recomputation of states that have been already considered.



Example: Gambling game
We shall illustrate forward recursion in the context of the Gambling game instance previously discussed. We begin the forward pass by considering

At this point we have not computed yet , which are needed to compute ; we proceed and compute these items. Note that , therefore one can leverage memoization and perform the necessary computations only once.


- Computation of





We have now computed for all that are needed to compute . However, this has led to additional suspended recursions involving . We proceed and compute these values.


- Computation of






Since stage 4 is the last stage in our system, represent boundary conditions that are easily computed as follows.

- Boundary conditions

At this point it is possible to proceed and recover the optimal policy and its value via a backward pass involving, at first, stage 3
- Backward pass involving







and, then, stage 2.
- Backward pass involving






We finally recover the value of an optimal policy

This is the optimal policy that has been previously illustrated. Note that there are multiple optimal policies leading to the same optimal value ; for instance, in the first game one may either bet $1 or $2.

Python implementation. The one that follows is a complete Python implementation of this example.
from typing import List, Tuple
import memoize as mem
import functools
class memoize:
def __init__(self, func):
self.func = func
self.memoized = {}
self.method_cache = {}
def __call__(self, *args):
return self.cache_get(self.memoized, args, lambda: self.func(*args))
def __get__(self, obj, objtype):
return self.cache_get(
self.method_cache,
obj,
lambda: self.__class__(functools.partial(self.func, obj)),
)
def cache_get(self, cache, key, func):
try:
return cache[key]
except KeyError:
cache[key] = func()
return cache[key]
def reset(self):
self.memoized = {}
self.method_cache = {}
class State:
"""the state of the gambler's ruin problem"""
def __init__(self, t: int, wealth: float):
"""state constructor
Arguments:
t {int} -- time period
wealth {float} -- initial wealth
"""
self.t, self.wealth = t, wealth
def __eq__(self, other):
return self.__dict__ == other.__dict__
def __str__(self):
return str(self.t) + " " + str(self.wealth)
def __hash__(self):
return hash(str(self))
class GamblersRuin:
def __init__(
self,
bettingHorizon: int,
targetWealth: float,
pmf: List[List[Tuple[int, float]]],
):
"""the gambler's ruin problem
Arguments:
bettingHorizon {int} -- betting horizon
targetWealth {float} -- target wealth
pmf {List[List[Tuple[int, float]]]} -- probability mass function
"""
# initialize instance variables
self.bettingHorizon, self.targetWealth, self.pmf = (
bettingHorizon,
targetWealth,
pmf,
)
# lambdas
self.ag = lambda s: [
i for i in range(0, min(self.targetWealth // 2, s.wealth) + 1)
] # action generator
self.st = lambda s, a, r: State(
s.t + 1, s.wealth - a + a * r
) # state transition
self.iv = (
lambda s, a, r: 1 if s.wealth - a + a * r >= self.targetWealth else 0
) # immediate value function
self.cache_actions = {} # cache with optimal state/action pairs
def f(self, wealth: float) -> float:
s = State(0, wealth)
return self._f(s)
def q(self, t: int, wealth: float) -> float:
s = State(t, wealth)
return self.cache_actions[str(s)]
@memoize
def _f(self, s: State) -> float:
# Forward recursion
v = max(
[
sum(
[
p[1]
* (
self._f(self.st(s, a, p[0]))
if s.t < self.bettingHorizon - 1
else self.iv(s, a, p[0])
) # future value
for p in self.pmf[s.t]
]
) # random variable realisations
for a in self.ag(s)
]
) # actions
opt_a = (
lambda a: sum(
[
p[1]
* (
self._f(self.st(s, a, p[0]))
if s.t < self.bettingHorizon - 1
else self.iv(s, a, p[0])
)
for p in self.pmf[s.t]
]
)
== v
)
q = [k for k in filter(opt_a, self.ag(s))] # retrieve best action list
self.cache_actions[str(s)] = (
q[0] if bool(q) else None
) # store an action in dictionary
return v # return value
instance = {
"bettingHorizon": 4,
"targetWealth": 6,
"pmf": [[(0, 0.6), (2, 0.4)] for i in range(0, 4)],
}
gr, initial_wealth = GamblersRuin(**instance), 2
# f_1(x) is gambler's probability of attaining $targetWealth at the end of bettingHorizon
print("f_1(" + str(initial_wealth) + "): " + str(gr.f(initial_wealth)))
# Recover optimal action for period 2 when initial wealth at the beginning of period 2 is $1.
t, initial_wealth = 1, 1
print(
"b_" + str(t + 1) + "(" + str(initial_wealth) + "): " + str(gr.q(t, initial_wealth))
)
Java implementation. GamblersRuin.java is a standalone Java 8 implementation of the above example.
Approximate dynamic programming
An introduction to approximate dynamic programming is provided by (Powell 2009).
Further reading
- Bellman, R. (1957), Dynamic Programming, Princeton University Press, ISBN 978-0-486-42809-3. Dover paperback edition (2003).
- Ross, S. M.; Bimbaum, Z. W.; Lukacs, E. (1983), Introduction to Stochastic Dynamic Programming, Elsevier, ISBN 978-0-12-598420-1.
- Bertsekas, D. P. (2000), Dynamic Programming and Optimal Control (2nd ed.), Athena Scientific, ISBN 978-1-886529-09-0. In two volumes.
- Powell, W. B. (2009), "What you should know about approximate dynamic programming", Naval Research Logistics, 56 (1): 239–249, CiteSeerX 10.1.1.150.1854, doi:10.1002/nav.20347, S2CID 7134937
See also
- Control theory – Branch of engineering and mathematics
- Dynamic programming – Problem optimization method
- Reinforcement learning – Field of machine learning
- Stochastic control – Probabilistic optimal control
- Stochastic process – Collection of random variables
- Stochastic programming – Framework for modeling optimization problems that involve uncertainty
References
- ↑ This problem is adapted from W. L. Winston, Operations Research: Applications and Algorithms (7th Edition), Duxbury Press, 2003, chap. 19, example 3.