A register file is an array of processor registers in a central processing unit (CPU). The instruction set architecture of a CPU will almost always define a set of registers which are used to stage data between memory and the functional units on the chip. The register file is part of the architecture and visible to the programmer, as opposed to the concept of transparent caches. In simpler CPUs, these architectural registers correspond one-for-one to the entries in a physical register file (PRF) within the CPU. More complicated CPUs use register renaming, so that the mapping of which physical entry stores a particular architectural register changes dynamically during execution.
Modern integrated circuit-based register files are usually implemented by way of fast static RAMs with multiple ports. Such RAMs are distinguished by having dedicated read and write ports, whereas ordinary multiported SRAMs will usually read and write through the same ports. Register banking is the method of using a single name to access multiple different physical registers depending on the operating mode.
Register-bank switching
Register files may be clubbed together as register banks.[1] A processor may have more than one register bank.
ARM processors have both banked and unbanked registers. While all modes always share the same physical registers for the first eight general-purpose registers, R0 to R7, the physical register which the banked registers, R8 to R14, point to depends on the operating mode the processor is in.[2] Notably, Fast Interrupt Request (FIQ) mode has its own bank of registers for R8 to R12, with the architecture also providing a private stack pointer (R13) for every interrupt mode.
x86 processors use context switching and fast interrupt for switching between instruction, decoder, GPRs and register files, if there is more than one, before the instruction is issued, but this is only existing on processors that support superscalar. However, context switching is a totally different mechanism to ARM's register bank within the registers.
The MODCOMP and the later 8051-compatible processors use bits in the program status word to select the currently active register bank.
Implementation

The usual layout convention is that a simple array is read out vertically. That is, a single word line, which runs horizontally, causes a row of bit cells to put their data on bit lines, which run vertically. Sense amps, which convert low-swing read bitlines into full-swing logic levels, are usually at the bottom (by convention). Larger register files are then sometimes constructed by tiling mirrored and rotated simple arrays.
Register files have one word line per entry per port, one bit line per bit of width per read port, and two bit lines per bit of width per write port. Each bit cell also has a Vdd and Vss. Therefore, the wire pitch area increases as the square of the number of ports, and the transistor area increases linearly.[3] At some point, it may be smaller and/or faster to have multiple redundant register files, with smaller numbers of read ports, rather than a single register file with all the read ports. The MIPS R8000's integer unit, for example, had a 9 read 4 write port 32 entry 64-bit register file implemented in a 0.7 µm process, which could be seen when looking at the chip from arm's length.
Two popular approaches to dividing registers into multiple register files are the distributed register file configuration and the partitioned register file configuration.[3]
In principle, any operation that could be done with a 64-bit-wide register file with many read and write ports could be done with a single 8-bit-wide register file with a single read port and a single write port. However, the bit-level parallelism of wide register files with many ports allows them to run much faster and thus, they can do operations in a single cycle that would take many cycles with fewer ports or a narrower bit width or both.
The width in bits of the register file is usually the number of bits in the processor word size. Occasionally it is slightly wider in order to attach "extra" bits to each register, such as the poison bit. If the width of the data word is different than the width of an address—or in some cases, such as the 68000, even when they are the same width—the address registers are in a separate register file than the data registers.
Decoder
- The decoder is often broken into pre-decoder and decoder proper.
- The decoder is a series of AND gates that drive word lines.
- There is one decoder per read or write port. If the array has four read and two write ports, for example, it has 6 word lines per bit cell in the array, and six AND gates per row in the decoder. Note that the decoder has to be pitch matched to the array, which forces those AND gates to be wide and short
Array
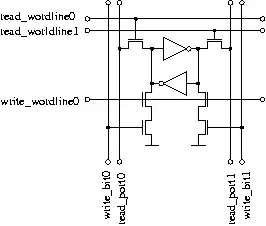
The basic scheme for a bit cell:
- State is stored in pair of inverters.
- Data is read out by NMOS transistor to a bit line.
- Data is written by shorting one side or the other to ground through a two-NMOS stack.
- So: read ports take one transistor per bit cell, write ports take four.
Many optimizations are possible:
- Sharing lines between cells, for example, Vdd and Vss.
- Read bit lines are often precharged to something between Vdd and Vss.
- Read bit lines often swing only a fraction of the way to Vdd or Vss. A sense amplifier converts this small-swing signal into a full logic level. Small swing signals are faster because the bit line has little drive but a great deal of parasitic capacitance.
- Write bit lines may be braided, so that they couple equally to the nearby read bitlines. Because write bitlines are full swing, they can cause significant disturbances on read bitlines.
- If Vdd is a horizontal line, it can be switched off, by yet another decoder, if any of the write ports are writing that line during that cycle. This optimization increases the speed of the write.
- Techniques that reduce the energy used by register files are useful in low-power electronics[4]
Microarchitecture
Most register files make no special provisions to prevent multiple write ports from writing to the same entry simultaneously. Instead, the instruction scheduling hardware ensures that only one instruction in any particular cycle writes a particular entry. If multiple instructions targeting the same register are issued, all but one have their write enables turned off.
The crossed inverters take some finite time to settle after a write operation, during which a read operation will either take longer or return garbage. It is common to have bypass multiplexers that bypass written data to the read ports when a simultaneous read and write to the same entry is commanded. These bypass multiplexers are often part of a larger bypass network that forwards results which have not yet been committed between functional units.
The register file is usually pitch-matched to the datapath that it serves. Pitch matching avoids having many busses passing over the datapath turn corners, which would use a lot of area. But since every unit must have the same bit pitch, every unit in the datapath ends up with the bit pitch forced by the widest unit, which can waste area in the other units. Register files, because they have two wires per bit per write port, and because all the bit lines must contact the silicon at every bit cell, can often set the pitch of a datapath.
Area can sometimes be saved on machines with multiple units in a datapath by having two datapaths side-by-side, each of which has smaller bit pitch than a single datapath would have. This case usually forces multiple copies of a register file, one for each datapath.
The Alpha 21264 (EV6), for instance, was the first large micro-architecture to implement a "Shadow Register File Architecture". It had two copies of the integer register file and two copies of the floating point register located in its front end (future and scaled file, each containing 2 read and 2 write ports), and took an extra cycle to propagate data between the two during a context switch. The issuing logic attempted to reduce the number of operations forwarding data between the two and greatly improved its integer performance, and helped reduce the impact of the limited number of general-purpose registers in superscalar architectures with speculative execution. This design was later adapted by SPARC, MIPS and some of the later x86 implementations.
The MIPS uses multiple register files as well. The R8000 floating-point unit had two copies of the floating-point register file, each with four write and four read ports, and wrote both copies at the same time with a context switch. However, it did not support integer operations, and the integer register file still remained as such. Later, shadow register files were abandoned in newer designs in favor of the embedded market.
The SPARC uses a "Shadow Register File Architecture" as well for its high-end line. It has up to 4 copies of integer register files (future, retired, scaled, and scratched, each containing 7 read 4 write port) and 2 copies of the floating point register file. However, unlike Alpha and x86, they are located in the backend as a retire unit right after its out-of-order unit and renaming register files. The shadow registers do not load instructions during instruction fetching and decoding stages and a context switch is unnecessary in this design.
IBM uses the same mechanism as many major microprocessors, deeply merging the register file with the decoder, but its register files work independently of the decoder side and do not involve context switching, which is different from Alpha and x86. Most of its register files do not only serve its dedicated decoder, but up to the thread level. For example, POWER8 has up to 8 instruction decoders, but up to 32 register files of 32 general purpose registers each (4 read and 4 write ports) to facilitate simultaneous multithreading, as its parallel instructions cannot be used across any other register file due to the lack of a context switch.
In the x86 processor line, a typical pre-486 CPU did not have an individual register file, as all general purpose registers worked directly with the decoder, and the x87 push stack was located within the floating-point unit itself. Starting with the Pentium, a typical Pentium-compatible x86 processor is integrated with one copy of a single-port architectural register file containing 6 general-purpose registers, 4 control registers, 8 debug registers (two reserved), 1 stack pointer register, 1 stack base register, 1 instruction pointer, 1 flags register, and 6 segment registers.
One copy of 8 x87 FP push down stack by default, MMX register were virtually simulated from x87 stack and require x86 register to supplying MMX instruction and aliases to exist stack. On P6, the instruction independently can be stored and executed in parallel in early pipeline stages before decoding into micro-operations and renaming in out-of-order execution. Beginning with P6, all register files do not require additional cycle to propagate the data, register files like architectural and floating point are located between code buffer and decoders, called "retire buffer", Reorder buffer and OoOE and connected within the ring bus (16 bytes). The register file itself still remains one x86 register file and one x87 stack and both serve as retirement storing. Its x86 register file was enlarged to dual-ported to increase bandwidth for result storage. Registers like debug/condition code/control/unnamed/flag were stripped from the main register file and placed into individual files between the micro-op ROM and instruction sequencer. Only inaccessible registers like the segment register are now separated from the general-purpose register file (except the instruction pointer); they are now located between the scheduler and instruction allocator, in order to facilitate register renaming and out-of-order execution. The x87 stack was later merged with the floating-point register file after a 128-bit XMM register debuted in Pentium III, but the XMM register file is still located separately from x86 integer register files.
Later P6 implementations (Pentium M, Yonah) introduced a "Shadow Register File Architecture" that expanded to 2 copies of dual-ported integer architectural register files and consist with context switch (between future and retired file and scaled file using the same trick used between integer and floating-point). This was done in order to solve the register bottleneck that existed in the x86 architecture after micro-operation fusion is introduced, but it is still have 8 entries 32 bit architectural registers for total 32 bytes in capacity per file (segment register and instruction pointer remain within the file, though they are inaccessible by program) as speculative file. The second file is served as a scaled shadow register file, which without context switch the scaled file cannot store some instruction independently. Some instruction from SSE2/SSE3/SSSE3 require this feature for integer operation, for example instruction like PSHUFB, PMADDUBSW, PHSUBW, PHSUBD, PHSUBSW, PHADDW, PHADDD, PHADDSW would require loading EAX/EBX/ECX/EDX from both register files, though it was uncommon for an x86 processor to make use of another register file with the same instruction. Most of time, the second file is served as a scale retired file. The Pentium M architecture still has one dual-ported floating-point register file (8 entries MM/XMM) shared with three decoders, and the FP register file does not have a shadow register file along with it, as its shadow-register-file architecture did not including floating-point functions. In processors after P6, the architectural register files are external and located in the processor's backend after the retired file, as opposed to the internal register file located in the inner core for register renaming/reorder buffer. However, in Core 2 it is now housed within a unit called the "register alias table" (RAT), located with instruction allocator but have same size of register size as retirement. Core 2 increased the inner ring bus to 24 bytes (allow more than 3 instructions to be decoded) and extended its register file from dual-ported (one read/one write) to quad-ported (two read/two write), register still remain 8 entries in 32 bit and 32 bytes (not including 6 segment register and one instruction pointer as they are unable to be access in the file by any code/instruction) in total file size and expanded to 16 entries in x64 for total 128 bytes size per file. From Pentium M as its pipeline port and decoder increased, but they're located with allocator table instead of code buffer. Its FP XMM register file are also increase to quad-ported (2 read/2 write), register still remain 8 entries in 32 bit and extended to 16 entries in x64 mode and number still remain 1 as its shadow-register-file architecture is not including floating point/SSE functions.
In later x86 implementations, like Nehalem and later processors, both integer and floating point registers are now incorporated into a unified octa-ported (six read and two write) general-purpose register file (8 + 8 in 32-bit and 16 + 16 in x64 per file), while the register file extended to 2 with enhanced "Shadow Register File Architecture" in favorite of executing hyper threading and each thread uses independent register files for its decoder. Later Sandy bridge and onward replaced shadow register table and architectural registers with much large and yet more advance physical register file before decoding to the reorder buffer. Randered that Sandy Bridge and onward no longer carry an architectural register.
On the Atom line was the modern simplified revision of P5. It includes single copies of register file share with thread and decoder. The register file is a dual-port design, 8/16 entries GPRS, 8/16 entries debug register and 8/16 entries condition code are integrated in the same file. However it has an eight-entries 64 bit shadow based register and an eight-entries 64 bit unnamed register that are now separated from main GPRs unlike the original P5 design and located after the execution unit, and the file of these registers is single-ported and not expose to instruction like scaled shadow register file found on Core/Core2 (shadow register file are made of architectural registers and Bonnell did not due to not have "Shadow Register File Architecture"), however the file can be use for renaming purpose due to lack of out of order execution found on Bonnell architecture. It also had one copy of XMM floating point register file per thread. The difference from Nehalem is Bonnell do not have a unified register file and has no dedicated register file for its hyper threading. Instead, Bonnell uses a separate rename register for its thread despite it is not out of order. Similar to Bonnell, Larrabee and Xeon Phi also each have only one general-purpose integer register file, but the Larrabee has up to 16 XMM register files (8 entries per file), and the Xeon Phi has up to 128 AVX-512 register files, each containing 32 512-bit ZMM registers for vector instruction storage, which can be as big as L2 cache.
There are some other of Intel's x86 lines that don't have a register file in their internal design, Geode GX and Vortex86 and many embedded processors that aren't Pentium-compatible or reverse-engineered early 80x86 processors. Therefore, most of them don't have a register file for their decoders, but their GPRs are used individually. Pentium 4 (based on the NetBurst microarchitecture), on the other hand, does not have a register file for its decoder, as its x86 GPRs didn't exist within its structure, due to the introduction of a physical unified renaming register file (similar to Sandy Bridge, but slightly different due to the inability of Pentium 4 to use the register before naming) for attempting to replace the architectural register file and skip the x86 decoding scheme. Instead it uses SSE for integer execution and storage before the ALU and after result, SSE2/SSE3/SSSE3 use the same mechanism as well for its integer operation.
AMD's early design like K6 do not have a register file like Intel and do not support "Shadow Register File Architecture" as its lack of context switch and bypass inverter that are necessary require for a register file to function appropriately. Instead they use a separate GPRs that directly link to a rename register table for its OoOE CPU with a dedicated integer decoder and floating decoder. The mechanism is similar to Intel's pre-Pentium processor line. For example, the K6 processor has four int (one eight-entries temporary scratched register file + one eight-entries future register file + one eight-entries fetched register file + an eight-entries unnamed register file) and two FP rename register files (two eight-entries x87 ST file one goes fadd and one goes fmov) that directly link with its x86 EAX for integer renaming and XMM0 register for floating point renaming, but later Athlon included "shadow register" in its front end, it's scaled up to 40 entries unified register file for in order integer operation before decoded, the register file contain 8 entries scratch register + 16 future GPRs register file + 16 unnamed GPRs register file. In later AMD designs it abandons the shadow register design and favored to K6 architecture with individual GPRs direct link design. Like Phenom, it has three int register files and two SSE register files that are located in the physical register file directly linked with GPRs. However, it scales down to one integer + one floating-point on Bulldozer. Like early AMD designs, most of the x86 manufacturers like Cyrix, VIA, DM&P, and SIS used the same mechanism as well, resulting in a lack of integer performance without register renaming for their in-order CPU. Companies like Cyrix and AMD had to increase cache size in hope to reduce the bottleneck. AMD's SSE integer operation work in a different way than Core 2 and Pentium 4; it uses its separate renaming integer register to load the value directly before the decode stage. Though theoretically it will only need a shorter pipeline than Intel's SSE implementation, but generally the cost of branch prediction are much greater and higher missing rate than Intel, and it would have to take at least two cycles for its SSE instruction to be executed regardless of instruction wide, as early AMDs implementations could not execute both FP and Int in an SSE instruction set like Intel's implementation did.
Unlike Alpha, SPARC, and MIPS that only allows one register file to load/fetch one operand at the time; it would require multiple register files to achieve superscale. The ARM processor on the other hand does not integrate multiple register files to load/fetch instructions. ARM GPRs have no special purpose to the instruction set (the ARM ISA does not require accumulator, index, and stack/base points. Registers do not have an accumulator and base/stack point can only be used in thumb mode). Any GPRs can propagate and store multiple instructions independently in smaller code size that is small enough to be able to fit in one register and its architectural register act as a table and shared with all decoder/instructions with simple bank switching between decoders. The major difference between ARM and other designs is that ARM allows to run on the same general-purpose register with quick bank switching without requiring additional register file in superscalar. Despite x86 sharing the same mechanism with ARM that its GPRs can store any data individually, x86 will confront data dependency if more than three non-related instructions are stored, as its GPRs per file are too small (eight in 32 bit mode and 16 in 64 bit, compared to ARM's 13 in 32 bit and 31 in 64 bit) for data, and it is impossible to have superscalar without multiple register files to feed to its decoder (x86 code is big and complex compared to ARM). Because most x86's front-ends have become much larger and much more power hungry than the ARM processor in order to be competitive (example: Pentium M & Core 2 Duo, Bay Trail). Some third-party x86 equivalent processors even became noncompetitive with ARM due to having no dedicated register-file architecture. Particularly for AMD, Cyrix and VIA that cannot bring any reasonable performance without register renaming and out of order execution, which leave only Intel Atom to be the only in-order x86 processor core in the mobile competition. This was until the x86 Nehalem processor merged both of its integer and floating point register into one single file, and the introduction of a large physical register table and enhanced allocator table in its front-end before renaming in its out-of-order internal core.
Register renaming
Processors that perform register renaming can arrange for each functional unit to write to a subset of the physical register file. This arrangement can eliminate the need for multiple write ports per bit cell, for large savings in area. The resulting register file, effectively a stack of register files with single write ports, then benefits from replication and subsetting the read ports. At the limit, this technique would place a stack of 1-write, 2-read regfiles at the inputs to each functional unit. Since regfiles with a small number of ports are often dominated by transistor area, it is best not to push this technique to this limit, but it is useful all the same.
Register windows
The SPARC ISA defines register windows, in which the 5-bit architectural names of the registers actually point into a window on a much larger register file, with hundreds of entries. Implementing multiported register files with hundreds of entries requires a large area. The register window slides by 16 registers when moved, so that each architectural register name can refer to only a small number of registers in the larger array, e.g. architectural register r20 can only refer to physical registers #20, #36, #52, #68, #84, #100, #116, if there are just seven windows in the physical file.
To save area, some SPARC implementations implement a 32-entry register file, in which each cell has seven "bits". Only one is read and writeable through the external ports, but the contents of the bits can be rotated. A rotation accomplishes in a single cycle a movement of the register window. Because most of the wires accomplishing the state movement are local, tremendous bandwidth is possible with little power.
This same technique is used in the R10000 register renaming mapping file, which stores a 6-bit virtual register number for each of the physical registers. In the renaming file, the renaming state is checkpointed whenever a branch is taken, so that when a branch is detected to be mispredicted, the old renaming state can be recovered in a single cycle. (See Register renaming.)
See also
References
- ↑ Wikibooks: Microprocessor Design/Register File#Register Bank.
- ↑ "ARM Architecture Reference Manual" (PDF). ARM Limited. July 2005. Retrieved 13 October 2021.
- 1 2 Johan Janssen. "Compiler Strategies for Transport Triggered Architectures". 2001. p. 169. p. 171-173.
- ↑ "Energy efficient asymmetrically ported register files" by Aneesh Aggarwal and M. Franklin. 2003.
External links
- Register file design considerations in dynamically scheduled processors - Farkas, Jouppi, Chow - 1995