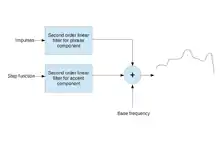
The Fujisaki model is a superpositional model for representing F0 contour of speech.
According to the model, F0 contour is generated as a result of the superposition of the outputs of two second order linear filters with a base frequency value. The second order linear filters are for generating the phrase and accent components of speech. The base frequency is the minimum frequency value of the speaker. In other words, F0 contour is obtained by adding base frequency, phrase components and accent components. The model was proposed by Hiroya Fujisaki.
where


![{\displaystyle G_{ai}(t)=\min[\gamma _{j},\,1-(1+\beta _{j}t)\,\exp(-\beta _{j}t)]\quad \forall t\geq 0;=0\forall t\leq 0}](../I/0f9204d87f34877912fdbba71cbc0c6ca2c9290c.svg)
Where,
: bias level upon which all the phrase and accent components are superposed to form an contour,


: number of phrase commands,

: number of accent commands,

: magnitude of the ith phrase command,

: amplitude of the jth accent command,

: instant of occurrence of the ith phrase command,

: onset of the jth accent command,

: end of the jth accent command,

: natural angular frequency of the phrase control mechanism to the ith phrase command,

: natural angular frequency of the accent control mechanism to the jth accent command, and

: ceiling level of the accent component for the jth accent command.

References
- An Introduction to Text-to-Speech Synthesis[1]
- Keikichi Hirose; Hiroya Fujisaki; Mikio Yamaguchi (1984). "Synthesis by rule of voice fundamental frequency contours of spoken Japanese from linguistic information". IEEE.