FaceNet is a facial recognition system developed by Florian Schroff, Dmitry Kalenichenko and James Philbina, a group of researchers affiliated to Google. The system was first presented in the IEEE Conference on Computer Vision and Pattern Recognition held in 2015.[1] The system uses a deep convolutional neural network to learn a mapping (also called an embedding) from a set of face images to the 128-dimensional Euclidean space and the similarity between two face images is assessed based on the square of the Euclidean distance between the corresponding normalized vectors in the 128-dimensional Euclidean space. The system used the triplet loss function as the cost function and introduced a new online triplet mining method. The system achieved an accuracy of 99.63% which is the highest score on Labeled Faces in the Wild dataset in the unrestricted with labeled outside data protocol.[2]
Structure
Basic structure
The structure of the FaceNet facenet recognition system is represented schematically in Figure 1.

For training, the researchers used as input batches of about 1800 images in which for each identity there were about 40 similar images and several randomly sampled images relating to other identities. These batches were fed to a deep convolutional neural network and the network was trained using stochastic gradient descent method with standard backpropagation and the Adaptive Gradient Optimizer (AdaGrad) algorithm. The learning rate was initially set at 0.05 which was later lowered while finalizing the model.
Structure of the CNN
The researchers used used two types of architectures, which they called NN1 and NN2, and explored their trade-offs. The practical differences between the models lie in the difference of parameters and FLOPS. The details of the NN1 model are presented in the table below.
| Layer | Size-in (rows × cols × #filters) | Size-out (rows × cols × #filters) | Kernel (rows × cols, stride) | Parameters | FLOPS |
|---|---|---|---|---|---|
| conv1 | 220×220×3 | 110×110×64 | 7×7×3, 2 | 9K | 115M |
| pool1 | 110×110×64 | 55×55×64 | 3×3×64, 2 | 0 | — |
| rnorm1 | 55×55×64 | 55×55×64 | 0 | ||
| conv2a | 55×55×64 | 55×55×64 | 1×1×64, 1 | 4K | 13M |
| conv2 | 55×55×64 | 55×55×192 | 3×3×64, 1 | 111K | 335M |
| rnorm2 | 55×55×192 | 55×55×192 | 0 | ||
| pool2 | 55×55×192 | 28×28×192 | 3×3×192, 2 | 0 | |
| conv3a | 28×28×192 | 28×28×192 | 1×1×192, 1 | 37K | 29M |
| conv3 | 28×28×192 | 28×28×384 | 3×3×192, 1 | 664K | 521M |
| pool3 | 28×28×384 | 14×14×384 | 3×3×384, 2 | 0 | |
| conv4a | 14×14×384 | 14×14×384 | 1×1×384, 1 | 148K | 29M |
| conv4 | 14×14×384 | 14×14×256 | 3×3×384, 1 | 885K | 173M |
| conv5a | 14×14×256 | 14×14×256 | 1×1×256, 1 | 66K | 13M |
| conv5 | 14×14×256 | 14×14×256 | 3×3×256, 1 | 590K | 116M |
| conv6a | 14×14×256 | 14×14×256 | 1×1×256, 1 | 66K | 13M |
| conv6 | 14×14×256 | 14×14×256 | 3×3×256, 1 | 590K | 116M |
| pool4 | 14×14×256 | 3×3×256, 2 | 7×7×256 | 0 | |
| concat | 7×7×256 | 7×7×256 | 0 | ||
| fc1 | 7×7×256 | 1×32×128 | maxout p=2 | 103M | 103M |
| fc2 | 1×32×128 | 1×32×128 | maxout p=2 | 34M | 34M |
| fc7128 | 1×32×128 | 1×1×128 | 524K | 0.5M | |
| L2 | 1×1×128 | 1×1×128 | 0 | ||
| Total | 140M | 1.6B |
Triplet loss function
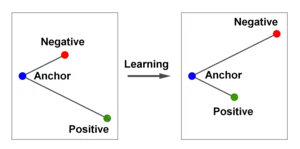
The loss function that was used in the FaceNet system was called the "Triplet Loss Function". This was a novel idea introduced by the developers of the FaceNet system. This function is defined using certain triplets of the form of training images. In this triplet, (called an "anchor image") denotes the image of a person, (called a "positive image") denotes some other image of the person whose image is and (called a "negative image") denotes the image of some other person different from the person whose image is . Let be some image and let be the embedding of in the 128-dimensional Euclidean space. It shall be assumed that the L2-norm of is unity. (The L2 norm of a vector in a finite dimensional Euclidean space is denoted by .) We pick such triplets from the training data set and let there be such triplets and be a typical triplet. The training is to ensure that, after learning, the following condition called the "triplet constraint" should be satisfied by all triplets in the training data set:











where is a constant called the margin and its value has to be set manually. Its value has been set as 0.2.

Thus, the function to be minimized is the following function called the triplet loss function:

Selection of triplets
In general the number of triplets of the form is very large. To make computations faster, the Google researchers considered only those triplets which violate the triplet constraint. For this, for a given anchor image they chose that positive image for which is maximum (such a positive image was called a "hard positive image") and that negative image for which is minimum (such a positive image was called a "hard negative image"). since using the whole training data set to determine the hard positive and hard negative images was computationally expensive and infeasible, the researchers experimented with several methods for selecting the triplets.





- Generate triplets offline computing the minimum and maximum on a subset of the data.
- Generate triplets online by selecting the hard positive/negative examples from within a mini-batch.
Performance
On the widely used Labeled Faces in the Wild (LFW) dataset, the FaceNet system achieved an accuracy of 99.63% which is the highest score on LFW in the unrestricted with labeled outside data protocol.[2] On YouTube Faces DB the system achieved an accuracy of 95.12%.[1]
See also
Further reading
- Rajesh Gopakumar; Karunagar A; Kotegar, M.; Vishal Anand (September 2023). "A Quantitative Study on the FaceNet System": in Proceedings of ICACCP 2023. Singapore: Springer Nature. pp. 211–222. ISBN 9789819942848.
- Ivan William; De Rosal Ignatius Moses Setiadi; Eko Hari Rachmawanto; Heru Agus Santoso; Christy Atika Sari (2019). "Face Recognition using FaceNet (Survey, Performance Test, and Comparison)" in Proceedings of Fourth International Conference on Informatics and Computing. IEEE Xplore. Retrieved 6 October 2023.
- For a discussion on the vulnerabilities of Facenet-based face recognition algorithms in applications to the Deepfake videos: Pavel Korshunov; Sébastien Marcel (2022). "The Threat of Deepfakes to Computer and Human Visions" in: Handbook of Digital Face Manipulation and Detection From DeepFakes to Morphing Attacks (PDF). Springer. pp. 97–114. ISBN 978-3-030-87664-7. Retrieved 5 October 2023.
- For a discussion on applying FaceNet for verifying faces in Android: Vasco Correia Veloso (January 2022). Hands-On Artificial Intelligence for Android. BPB Publications. ISBN 9789355510242. Amazon
References
- 1 2 Florian Schroff; Dmitry Kalenichenko; James Philbin. "FaceNet: A Unified Embedding for Face Recognition and Clustering" (PDF). The Computer Vision Foundation. Retrieved 4 October 2023.
- 1 2 Erik Learned-Miller; Gary Huang; Aruni RoyChowdhury; Haoxiang Li; Gang Hua (April 2016). "Labeled Faces in the Wild: A Survey". Advances in Face Detection and Facial Image Analysis (PDF). Springer. pp. 189–248. Retrieved 5 October 2023.