Extendible hashing is a type of hash system which treats a hash as a bit string and uses a trie for bucket lookup.[1] Because of the hierarchical nature of the system, re-hashing is an incremental operation (done one bucket at a time, as needed). This means that time-sensitive applications are less affected by table growth than by standard full-table rehashes.
Extendible hashing was described by Ronald Fagin in 1979. Practically all modern filesystems use either extendible hashing or B-trees. In particular, the Global File System, ZFS, and the SpadFS filesystem use extendible hashing.[2]
Example
Assume that the hash function returns a string of bits. The first i bits of each string will be used as indices to figure out where they will go in the "directory" (hash table). Additionally, i is the smallest number such that the index of every item in the table is unique.

Keys to be used:

Let's assume that for this particular example, the bucket size is 1. The first two keys to be inserted, k1 and k2, can be distinguished by the most significant bit, and would be inserted into the table as follows:
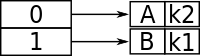
Now, if k3 were to be hashed to the table, it wouldn't be enough to distinguish all three keys by one bit (because both k3 and k1 have 1 as their leftmost bit). Also, because the bucket size is one, the table would overflow. Because comparing the first two most significant bits would give each key a unique location, the directory size is doubled as follows:

And so now k1 and k3 have a unique location, being distinguished by the first two leftmost bits. Because k2 is in the top half of the table, both 00 and 01 point to it because there is no other key to compare to that begins with a 0.
The above example is from Fagin et al. (1979).
Further detail

Now, k4 needs to be inserted, and it has the first two bits as 01..(1110), and using a 2 bit depth in the directory, this maps from 01 to Bucket A. Bucket A is full (max size 1), so it must be split; because there is more than one pointer to Bucket A, there is no need to increase the directory size.
What is needed is information about:
- The key size that maps the directory (the global depth), and
- The key size that has previously mapped the bucket (the local depth)
In order to distinguish the two action cases:
- Doubling the directory when a bucket becomes full
- Creating a new bucket, and re-distributing the entries between the old and the new bucket
Examining the initial case of an extendible hash structure, if each directory entry points to one bucket, then the local depth should be equal to the global depth.
The number of directory entries is equal to 2global depth, and the initial number of buckets is equal to 2local depth.
Thus if global depth = local depth = 0, then 20 = 1, so an initial directory of one pointer to one bucket.
Back to the two action cases; if the bucket is full:
- If the local depth is equal to the global depth, then there is only one pointer to the bucket, and there is no other directory pointers that can map to the bucket, so the directory must be doubled.
- If the local depth is less than the global depth, then there exists more than one pointer from the directory to the bucket, and the bucket can be split.

Key 01 points to Bucket A, and Bucket A's local depth of 1 is less than the directory's global depth of 2, which means keys hashed to Bucket A have only used a 1 bit prefix (i.e. 0), and the bucket needs to have its contents split using keys 1 + 1 = 2 bits in length; in general, for any local depth d where d is less than D, the global depth, then d must be incremented after a bucket split, and the new d used as the number of bits of each entry's key to redistribute the entries of the former bucket into the new buckets.

Now,
is tried again, with 2 bits 01.., and now key 01 points to a new bucket but there is still in it ( and also begins with 01).


If had been 000110, with key 00, there would have been no problem, because would have remained in the new bucket A' and bucket D would have been empty.
(This would have been the most likely case by far when buckets are of greater size than 1 and the newly split buckets would be exceedingly unlikely to overflow, unless all the entries were all rehashed to one bucket again. But just to emphasize the role of the depth information, the example will be pursued logically to the end.)
So Bucket D needs to be split, but a check of its local depth, which is 2, is the same as the global depth, which is 2, so the directory must be split again, in order to hold keys of sufficient detail, e.g. 3 bits.

- Bucket D needs to split due to being full.
- As D's local depth = the global depth, the directory must double to increase bit detail of keys.
- Global depth has incremented after directory split to 3.
- The new entry is rekeyed with global depth 3 bits and ends up in D which has local depth 2, which can now be incremented to 3 and D can be split to D' and E.
- The contents of the split bucket D, , has been re-keyed with 3 bits, and it ends up in D'.
- K4 is retried and it ends up in E which has a spare slot.


Now, is in D and is tried again, with 3 bits 011.., and it points to bucket D which already contains so is full; D's local depth is 2 but now the global depth is 3 after the directory doubling, so now D can be split into bucket's D' and E, the contents of D, has its retried with a new global depth bitmask of 3 and ends up in D', then the new entry is retried with bitmasked using the new global depth bit count of 3 and this gives 011 which now points to a new bucket E which is empty. So goes in Bucket E.


Example implementation
Below is the extendible hashing algorithm in Python, with the disc block / memory page association, caching and consistency issues removed. Note a problem exists if the depth exceeds the bit size of an integer, because then doubling of the directory or splitting of a bucket won't allow entries to be rehashed to different buckets.
The code uses the least significant bits, which makes it more efficient to expand the table, as the entire directory can be copied as one block (Ramakrishnan & Gehrke (2003)).
Python example
PAGE_SZ = 10
class Page:
def __init__(self) -> None:
self.map = []
self.local_depth = 0
def full(self) -> bool:
return len(self.map) >= PAGE_SZ
def put(self, k, v) -> None:
for i, (key, value) in enumerate(self.map):
if key == k:
del self.map[i]
break
self.map.append((k, v))
def get(self, k):
for key, value in self.map:
if key == k:
return value
def get_local_high_bit(self):
return 1 << self.local_depth
class ExtendibleHashing:
def __init__(self) -> None:
self.global_depth = 0
self.directory = [Page()]
def get_page(self, k):
h = hash(k)
return self.directory[h & ((1 << self.global_depth) - 1)]
def put(self, k, v) -> None:
p = self.get_page(k)
full = p.full()
p.put(k, v)
if full:
if p.local_depth == self.global_depth:
self.directory *= 2
self.global_depth += 1
p0 = Page()
p1 = Page()
p0.local_depth = p1.local_depth = p.local_depth + 1
high_bit = p.get_local_high_bit()
for k2, v2 in p.map:
h = hash(k2)
new_p = p1 if h & high_bit else p0
new_p.put(k2, v2)
for i in range(hash(k) & (high_bit - 1), len(self.directory), high_bit):
self.directory[i] = p1 if i & high_bit else p0
def get(self, k):
return self.get_page(k).get(k)
if __name__ == "__main__":
eh = ExtendibleHashing()
N = 10088
l = list(range(N))
import random
random.shuffle(l)
for x in l:
eh.put(x, x)
print(l)
for i in range(N):
print(eh.get(i))
Notes
- ↑ Fagin et al. (1979).
- ↑ Mikuláš Patocka (2006). Design and Implementation of the Spad Filesystem (PDF) (Thesis). "Section 4.1.6 Extendible hashing: ZFS and GFS" and "Table 4.1: Directory organization in filesystems"
See also
References
- Fagin, R.; Nievergelt, J.; Pippenger, N.; Strong, H. R. (September 1979), "Extendible Hashing - A Fast Access Method for Dynamic Files", ACM Transactions on Database Systems, 4 (3): 315–344, doi:10.1145/320083.320092, S2CID 2723596
- Ramakrishnan, R.; Gehrke, J. (2003), Database Management Systems, 3rd Edition: Chapter 11, Hash-Based Indexing, pp. 373–378
- Silberschatz, Abraham; Korth, Henry; Sudarshan, S., Database System Concepts, Sixth Edition: Chapter 11.7, Dynamic Hashing
External links
 This article incorporates public domain material from Paul E. Black. "Extendible hashing". Dictionary of Algorithms and Data Structures. NIST.
This article incorporates public domain material from Paul E. Black. "Extendible hashing". Dictionary of Algorithms and Data Structures. NIST.- Extendible Hashing notes at Arkansas State University
- Extendible hashing notes
- Slides from the database System Concepts book on extendible hashing for hash based dynamic indices