Directional component analysis (DCA)[1][2][3] is a statistical method used in climate science for identifying representative patterns of variability in space-time data-sets such as historical climate observations,[1] weather prediction ensembles[2] or climate ensembles.[3]
The first DCA pattern is a pattern of weather or climate variability that is both likely to occur (measured using likelihood) and has a large impact (for a specified linear impact function, and given certain mathematical conditions: see below).
The first DCA pattern contrasts with the first PCA pattern, which is likely to occur, but may not have a large impact, and with a pattern derived from the gradient of the impact function, which has a large impact, but may not be likely to occur.
DCA differs from other pattern identification methods used in climate research, such as EOFs,[4] rotated EOFs[5] and extended EOFs[6] in that it takes into account an external vector, the gradient of the impact.
DCA provides a way to reduce large ensembles from weather forecasts[2] or climate models[3] to just two patterns. The first pattern is the ensemble mean, and the second pattern is the DCA pattern, which represents variability around the ensemble mean in a way that takes impact into account. DCA contrasts with other methods that have been proposed for the reduction of ensembles[7][8] in that it takes impact into account in addition to the structure of the ensemble.
Overview
Inputs
DCA is calculated from two inputs:[1][2][3]
- a multivariate dataset of weather or climate data, such as historical climate observations, or a weather or climate ensemble
- a linear impact function. The linear impact function is a function which defines a level of impact for every spatial pattern in the weather or climate data as a weighted sum of the values at different locations in the spatial pattern. An example is the mean value across the spatial pattern. The linear impact function can be generated as the first term in the multivariate Taylor series of a non-linear impact function.[3]
Formula
Consider a space-time data set , containing individual spatial pattern vectors , where the individual patterns are each considered as single samples from a multivariate normal distribution with mean zero and covariance matrix .



We define a linear impact function of a spatial pattern as , where is a vector of spatial weights.


The first DCA pattern is given in terms the covariance matrix and the weights by the proportional expression . [1][2][3]

The pattern can then be normalized to any length as required.[1]
Properties
If the weather or climate data is elliptically distributed (e.g., is distributed as a multivariate normal distribution or a multivariate t-distribution) then the first DCA pattern (DCA1) is defined as the spatial pattern with the following mathematical properties:
- DCA1 maximises probability density for a given value of impact[1]
- DCA1 maximises impact for a given value of probability density[1]
- DCA1 maximises the product of impact and probability density[3]
- DCA1 is the conditional expectation, conditional on exceeding a certain level of impact[3]
- DCA1 is the impact-weighted ensemble mean[3]
- Any modification of DCA1 will lead to a pattern that is either less extreme, or has a lower probability density.
Rainfall Example
For instance, in a rainfall anomaly dataset, using an impact metric defined as the total rainfall anomaly, the first DCA pattern is the spatial pattern that has the highest probability density for a given total rainfall anomaly. If the given total rainfall anomaly is chosen to have a large value, then this pattern combines being extreme in terms of the metric (i.e., representing large amounts of total rainfall) with being likely in terms of the pattern, and so is well suited as a representative extreme pattern.
Comparison with PCA
The main differences between Principal component analysis (PCA) and DCA are[1]
- PCA is a function of just the covariance matrix, and the first PCA pattern is defined so as to maximise explained variance
- DCA is a function of the covariance matrix and a vector direction (the gradient of the impact function), and the first DCA pattern is defined so as to maximise probability density for a given value of the impact metric
As a result, for unit vector spatial patterns:
- The first PCA spatial pattern always corresponds to a higher explained variance, but has a lower value of the impact metric (e.g., the total rainfall anomaly), except in degenerate cases
- The first DCA spatial pattern always corresponds to a higher value of the impact metric, but has a lower value of the explained variance, except in degenerate cases
The degenerate cases occur when the PCA and DCA patterns are equal.
Also, given the first PCA pattern, the DCA pattern can be scaled so that:
- The scaled DCA pattern has the same probability density as the first PCA pattern, but higher impact, or
- The scaled DCA pattern has the same impact as the first PCA pattern, but higher probability density.
Two Dimensional Example
Source:[1]
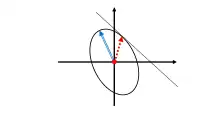
Figure 1 gives an example, which can be understood as follows:
- The two axes represent anomalies of annual mean rainfall at two locations, with the highest total rainfall anomaly values towards the top right corner of the diagram
- The joint variability of the rainfall anomalies at the two locations is assumed to follow a bivariate normal distribution
- The ellipse shows a single contour of probability density from this bivariate normal, with higher values inside the ellipse
- The red dot at the centre of the ellipse shows zero rainfall anomalies at both locations
- The blue parallel-line arrow shows the principal axis of the ellipse, which is also the first PCA spatial pattern vector
- In this case, the PCA pattern is scaled so that it touches the ellipse
- The diagonal straight line shows a line of constant positive total rainfall anomaly, assumed to be at some fairly extreme level
- The red dotted-line arrow shows the first DCA pattern, which points towards the point at which the diagonal line is tangent to the ellipse
- In this case, the DCA pattern is scaled so that it touches the ellipse
From this diagram, the DCA pattern can be seen to possess the following properties:
- Of all the points on the diagonal line, it is the one with the highest probability density
- Of all the points on the ellipse, it is the one with the highest total rainfall anomaly
- It has the same probability density as the PCA pattern, but represents higher total rainfall (i.e., points further towards the top right hand corner of the diagram)
- Any change of the DCA pattern will reduce either the probability density (if it moves out of the ellipse) or reduce the total rainfall anomaly (if it moves along or into the ellipse)
In this case the total rainfall anomaly of the PCA pattern is quite small, because of anticorrelations between the rainfall anomalies at the two locations. As a result, the first PCA pattern is not a good representative example of a pattern with large total rainfall anomaly, while the first DCA pattern is.
In dimensions the ellipse becomes an ellipsoid, the diagonal line becomes an dimensional plane, and the PCA and DCA patterns are vectors in dimensions.


Applications
Application to Climate Variability
DCA has been applied to the CRU data-set of historical rainfall variability[9] in order to understand the most likely patterns of rainfall extremes in the US and China.[1]
Application to Ensemble Weather Forecasts
DCA has been applied to ECMWF medium-range weather forecast ensembles in order to identify the most likely patterns of extreme temperatures in the ensemble forecast.[2]
Application to Ensemble Climate Model Projections
DCA has been applied to ensemble climate model projections in order to identify the most likely patterns of extreme future rainfall.[3]
Derivation of the First DCA Pattern
Source:[1]
Consider a space-time data-set , containing individual spatial pattern vectors , where the individual patterns are each considered as single samples from a multivariate normal distribution with mean zero and covariance matrix .
As a function of , the log probability density is proportional to .

We define a linear impact function of a spatial pattern as , where is a vector of spatial weights.
We then seek to find the spatial pattern that maximises the probability density for a given value of the linear impact function. This is equivalent to finding the spatial pattern that maximises the log probability density for a given value of the linear impact function, which is slightly easier to solve.
This is a constrained maximisation problem, and can be solved using the method of Lagrange multipliers.
The Lagrangian function is given by

Differentiating by and setting to zero gives the solution
Normalising so that is unit vector gives

This is the first DCA pattern.
Subsequent patterns can be derived which are orthogonal to the first, to form an orthonormal set and a method for matrix factorisation.
References
- 1 2 3 4 5 6 7 8 9 10 11 Jewson, S. (2020). "An Alternative to PCA for Estimating Dominant Patterns of Climate Variability and Extremes, with Application to U.S. and China Seasonal Rainfall". Atmosphere. 11 (4): 354. Bibcode:2020Atmos..11..354J. doi:10.3390/atmos11040354.
- 1 2 3 4 5 6 Scher, S.; Jewson, S.; Messori, G. (2021). "Robust Worst-Case Scenarios from Ensemble Forecasts". Weather and Forecasting. 36 (4): 1357–1373. Bibcode:2021WtFor..36.1357S. doi:10.1175/WAF-D-20-0219.1. S2CID 236300040.
- 1 2 3 4 5 6 7 8 9 10 Jewson, S.; Messori, G.; Barbato, G.; Mercogliano, P.; Mysiak, J.; Sassi, M. (2022). "Developing Representative Impact Scenarios From Climate Projection Ensembles, With Application to UKCP18 and EURO-CORDEX Precipitation". Journal of Advances in Modeling Earth Systems. 15 (1). doi:10.1029/2022MS003038. S2CID 254965361.
- ↑ Hannachi, A.; Jolliffe, I.; Stephenson, D. (2007). "Empirical orthogonal functions and related techniques in atmospheric science: A review". International Journal of Climatology. 27 (9): 1119. Bibcode:2007IJCli..27.1119H. doi:10.1002/joc.1499. S2CID 52232574.
- ↑ Mestas-Nunez, A. (2000). "Orthogonality properties of rotated empirical modes". International Journal of Climatology. 20 (12): 1509–1516. doi:10.1002/1097-0088(200010)20:12<1509::AID-JOC553>3.0.CO;2-Q.
- ↑ Fraedrich, K.; McBride, J.; Frank, W.; Wang, R. (1997). "Extended EOF Analysis of Tropical Disturbances: TOGA COARE". Journal of the Atmospheric Sciences. 41 (19): 2363. Bibcode:1997JAtS...54.2363F. doi:10.1175/1520-0469(1997)054<2363:EEAOTD>2.0.CO;2.
- ↑ Evans, J.; Ji, F.; Abramowitz, G.; Ekstrom, M. (2013). "Optimally choosing small ensemble members to produce robust climate simulations". Environmental Research Letters. 8 (4): 044050. Bibcode:2013ERL.....8d4050E. doi:10.1088/1748-9326/8/4/044050. S2CID 155021417.
- ↑ Herger, N.; Abramowitz, G.; Knutti, R.; Angelil, O.; Lehmann, K.; Sanderson, B. (2017). "Selecting a climate model subset to optimise key ensemble properties". Earth System Dynamics. 9: 135–151. doi:10.5194/esd-9-135-2018. hdl:20.500.11850/246202.
- ↑ Harris, I.; Jones, P.; Osborn, T.; Lister, D. (2013). "Updated high-resolution grids of monthly climatic observations— The CRU TS3.10 Dataset" (PDF). International Journal of Climatology. 34 (3): 623. Bibcode:2014IJCli..34..623H. doi:10.1002/joc.3711. S2CID 54866679.