
The CheiRank is an eigenvector with a maximal real eigenvalue of the Google matrix constructed for a directed network with the inverted directions of links. It is similar to the PageRank vector, which ranks the network nodes in average proportionally to a number of incoming links being the maximal eigenvector of the Google matrix with a given initial direction of links. Due to inversion of link directions the CheiRank ranks the network nodes in average proportionally to a number of outgoing links. Since each node belongs both to CheiRank and PageRank vectors the ranking of information flow on a directed network becomes two-dimensional.


Definition





For a given directed network the Google matrix is constructed in the way described in the article Google matrix. The PageRank vector is the eigenvector with the maximal real eigenvalue . It was introduced in[1] and is discussed in the article PageRank. In a similar way the CheiRank is the eigenvector with the maximal real eigenvalue of the matrix built in the same way as but using inverted direction of links in the initially given adjacency matrix. Both matrices and belong to the class of Perron–Frobenius operators and according to the Perron–Frobenius theorem the CheiRank and PageRank eigenvectors have nonnegative components which can be interpreted as probabilities.[2][3] Thus all nodes of the network can be ordered in a decreasing probability order with ranks for CheiRank and PageRank respectively. In average the PageRank probability is proportional to the number of ingoing links with .[4][5][6] For the World Wide Web (WWW) network the exponent where is the exponent for ingoing links distribution.[4][5] In a similar way the CheiRank probability is in average proportional to the number of outgoing links with with where is the exponent for outgoing links distribution of the WWW.[4][5] The CheiRank was introduced for the procedure call network of Linux Kernel software in,[7] the term itself was used in Zhirov.[8] While the PageRank highlights very well known and popular nodes, the CheiRank highlights very communicative nodes. Top PageRank and CheiRank nodes have certain analogy to authorities and hubs appearing in the HITS algorithm[9] but the HITS is query dependent while the rank probabilities and classify all nodes of the network. Since each node belongs both to CheiRank and PageRank we obtain a two-dimensional ranking of network nodes. There had been early studies of PageRank in networks with inverted direction of links[10][11] but the properties of two-dimensional ranking had not been analyzed in detail.




















Examples
An example of nodes distribution in the plane of PageRank and CheiRank is shown in Fig.1 for the procedure call network of Linux Kernel software.[7]
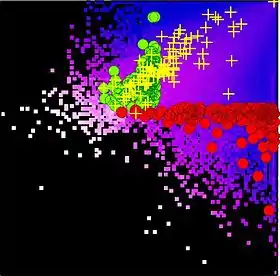


The dependence of on for the network of hyperlink network of Wikipedia English articles is shown in Fig.2 from Zhirov. The distribution of these articles in the plane of PageRank and CheiRank is shown in Fig.3 from Zhirov. The difference between PageRank and CheiRank is clearly seen from the names of Wikipedia articles (2009) with highest rank. At the top of PageRank we have 1.United States, 2.United Kingdom, 3.France while for CheiRank we find 1.Portal:Contents/Outline of knowledge/Geography and places, 2.List of state leaders by year, 3.Portal:Contents/Index/Geography and places. Clearly PageRank selects first articles on a broadly known subject with a large number of ingoing links while CheiRank selects first highly communicative articles with many outgoing links. Since the articles are distributed in 2D they can be ranked in various ways corresponding to projection of 2D set on a line. The horizontal and vertical lines correspond to PageRank and CheiRank, 2DRank combines properties of CheiRank and PageRank as it is discussed in Zhirov.[8] It gives top Wikipedia articles 1.India, 2.Singapore, 3.Pakistan.


The 2D ranking highlights the properties of Wikipedia articles in a new rich and fruitful manner. According to the PageRank the top 100 personalities described in Wikipedia articles have in 5 main category activities: 58 (politics), 10 (religion),17 (arts), 15 (science), 0 (sport) and thus the importance of politicians is strongly overestimated. The CheiRank gives respectively 15, 1, 52, 16, 16 while for 2DRank one finds 24, 5, 62, 7, 2. Such type of 2D ranking can find useful applications for various complex directed networks including the WWW.
CheiRank and PageRank naturally appear for the world trade network, or international trade, where they and linked with export and import flows for a given country respectively.[12]
Possibilities of development of two-dimensional search engines based on PageRank and CheiRank are considered.[13] Directed networks can be characterized by the correlator between PageRank and CheiRank vectors: in certain networks this correlator is close to zero (e.g. Linux Kernel network) while other networks have large correlator values (e.g. Wikipedia or university networks).[7][13]
Simple network example





A simple example of the construction of the Google matrices and , used for determination of the related PageRank and CheiRank vectors, is given below. The directed network example with 7 nodes is shown in Fig.4. The matrix , built with the rules described in the article Google matrix, is shown in Fig.5; the related Google matrix is and the PageRank vector is the right eigenvector of with the unit eigenvalue (). In a similar way, to determine the CheiRank eigenvector all directions of links in Fig.4 are inverted, then the matrix is built, according to the same rules applied for the network with inverted link directions, as shown in Fig.6. The related Google matrix is and the CheiRank vector is the right eigenvector of with the unit eigenvalue (). Here is the damping factor taken at its usual value.





See also
References
- ↑ Brin S.; Page L. (1998), "The anatomy of a large-scale hypertextual Web search engine", Computer Networks and ISDN Systems, 30 (1–7): 107, doi:10.1016/S0169-7552(98)00110-X, S2CID 7587743
- ↑ Langville, Amy N.; Carl Meyer (2006). Google's PageRank and Beyond. Princeton University Press. ISBN 0-691-12202-4.
- ↑ Austin, David (2008). "How Google Finds Your Needle in the Web's Haystack". AMS Feature Columns.
- 1 2 3 Donato D.; Laura L.; Leonardi S.; Millozzi S. (2004), "Large scale properties of the Webgraph", European Physical Journal B, 38 (2): 239, Bibcode:2004EPJB...38..239D, doi:10.1140/epjb/e2004-00056-6, S2CID 10640375
- 1 2 3 Pandurangan G.; Ranghavan P.; Upfal E. (2005), "Using PageRank to Characterize Web Structure", Internet Math., 3: 1, doi:10.1080/15427951.2006.10129114
- ↑ Litvak, N.; Scheinhardt, W.R.W.; Volkovich, Y. (2008), Probabilistic Relation between In-Degree and PageRank, Lecture Notes in Computer Science, vol. 4936, p. 72
- 1 2 3 Chepelianskii, Alexei D. (2010). "Towards physical laws for software architecture". arXiv:1003.5455 [cs.SE].
- 1 2 Zhirov A.O.; Zhirov O.V.; Shepelyansky D.L. (2010), "Two-dimensional ranking of Wikipedia articles", European Physical Journal B, 77 (4): 523, arXiv:1006.4270, Bibcode:2010EPJB...77..523Z, doi:10.1140/epjb/e2010-10500-7, S2CID 18014470
- ↑ Kleinberg, Jon (1999). "Authoritative sources in a hyperlinked environment". Journal of the ACM. 46 (5): 604–632. doi:10.1145/324133.324140. S2CID 221584113.
- ↑ Fogaras, D. (2003), Where to start browsing the web?, Lecture Notes in Computer Science, vol. 2877, p. 65
- ↑ Hrisitidis V.; Hwang H.; Papakonstantinou Y. (2008), "Authority-based keyword search in databases", ACM Trans. Database Syst., 33: 1, doi:10.1145/1331904.1331905, S2CID 11978441
- ↑ Ermann L.; Shepelyansky D.L. (2011). "Google matrix of the world trade network". Acta Physica Polonica A. 120 (6A): A. arXiv:1103.5027. Bibcode:2011AcPPA.120..158E. doi:10.12693/APhysPolA.120.A-158. S2CID 18315654.
- 1 2 Ermann L.; Chepelianskii A.D.; Shepelyansky D.L. (2011). "Towards two-dimensional search engines". Journal of Physics A: Mathematical and Theoretical. 45 (27): 275101. arXiv:1106.6215. Bibcode:2012JPhA...45A5101E. doi:10.1088/1751-8113/45/27/275101. S2CID 14827486.