 R terminal | |
| Paradigms | Multi-paradigm: procedural, object-oriented, functional, reflective, imperative, array[1] |
|---|---|
| Designed by | Ross Ihaka and Robert Gentleman |
| Developer | R Core Team |
| First appeared | August 1993 |
| Stable release | |
| Typing discipline | Dynamic |
| Platform | arm64 and x86-64 |
| License | GNU GPL v2 |
| Filename extensions | |
| Website | www |
| Influenced by | |
| Influenced | |
| Julia[6] | |
| |
R is a programming language for statistical computing and graphics. Created by statisticians Ross Ihaka and Robert Gentleman, R is also used for data mining, bioinformatics, and data analysis.[7]
The core R language is augmented by a large number of extension packages, containing reusable code, documentation, and sample data.
R software is open-source free software, licensed by the GNU Project, and available under the GNU General Public License. It is written primarily in C, Fortran, and R itself. Precompiled executables are provided for various operating systems. R is supported by the R Core Team and the R Foundation for Statistical Computing.
R has a native command line interface. Moreover, multiple third-party graphical user interfaces are available, such as RStudio -- an integrated development environment, and Jupyter -- a notebook interface.
History

.jpg.webp)
R was started by professors Ross Ihaka and Robert Gentleman as a programming language to teach introductory statistics at the University of Auckland.[8] The language was inspired by the S programming language, with most S programs able to run unaltered in R[5]. The language was also inspired by Scheme's lexical scoping, allowing for local variables.[1]
The name of the language, R, comes from being both an S language successor as well as the shared first letter of the authors, Ross and Robert.[9] Ihaka and Gentleman first shared binaries of R on the data archive StatLib and the s-news mailing list in August 1993.[10] Mailing lists for the R project began on 1 April 1997 preceding the release of version 0.50.[11] R officially became a GNU project on 5 December 1997 when version 0.60 released.[12] The first official 1.0 version was released on 29 February 2000.[13]
The Comprehensive R Archive Network (CRAN) was founded in 1997 by Kurt Hornik and Fritz Leisch to host R's source code, executable files, documentation, and user-created packages.[14] Its name and scope mimics the Comprehensive TeX Archive Network and the Comprehensive Perl Archive Network.[14] CRAN originally had three mirrors and 12 contributed packages.[15] As of December 2022, it has 103 mirrors[16] and 18,976 contributed packages.[17]
The R Core Team was formed in 1997 to further develop the language.[18] In April 2003, the R Foundation was founded as a non-profit organization to provide further support for the R project.[18]
Examples
Mean -- a measure of center
A numeric data set may have a central tendency — where some of the most typical data points reside.[19] The arithmetic mean (average) is the most commonly used measure of central tendency.[19] The mean of a numeric data set is the sum of the data points divided by the number of data points.[19] It is represented by the symbol .

- Let = a list of data points.
- Let = the number of data points.



Suppose a sample of four observations of Celsius temperature measurements were taken 12 hours apart.
- Let = a list of degrees Celsius data points of 30, 27, 31, 28.
This R computer program will output the mean of :
# The c() function "combines" a list into a single object.
x <- c( 30, 27, 31, 28 )
sum <- sum( x )
length <- length( x )
mean <- sum / length
message( "Mean:" )
print( mean )
Note: R can have the same identifier represent both a function name and its result. For more information, visit scope.
Output:
Mean:
[1] 29
This R program will execute the native mean() function to output the mean of x:

x <- c( 30, 27, 31, 28 )
message( "Mean:" )
print( mean( x ) )
Output:
Mean:
[1] 29
Standard Deviation -- a measure of dispersion
A standard deviation of a numeric data set is an indication of the average distance all the data points are from the mean.[20] For a data set with a small amount of variation, then each data point will be close to the mean, so the standard deviation will be small.[20] Standard deviation is represented by the symbol .

- Let = a list of data points.
- Let = the number of data points.

Suppose a sample of four observations of Celsius temperature measurements were taken 12 hours apart.
- Let = a list of degrees Celsius data points of 30, 27, 31, 28.
This R program will output the standard deviation of :
x <- c( 30, 27, 31, 28 )
distanceFromMean <- x - mean( x )
distanceFromMeanSquared <- distanceFromMean ** 2
distanceFromMeanSquaredSum <- sum( distanceFromMeanSquared )
variance <- distanceFromMeanSquaredSum / ( length( x ) - 1 )
standardDeviation <- sqrt( variance )
message( "Standard Deviation:" )
print( standardDeviation )
Output:
Standard Deviation:
[1] 1.825742
This R program will execute the native sd() function to output the standard deviation of :
x <- c( 30, 27, 31, 28 )
message( "Standard Deviation:" )
print( sd( x ) )
Output:
Standard Deviation:
[1] 1.825742
Linear regression -- a measure of relation

A phenomenon may be the result of one or more observable events. For example, the phenomenon of skiing accidents may be the result of having snow in the mountains. A method to measure whether or not a numeric data set is related to another data set is linear regression.[22]
- Let = a data set of independent data points, in which each point occurred at a specific time.
- Let = a data set of dependent data points, in which each point occurred at the same time of an independent data point.

If a linear relationship exists, then a scatter plot of the two data sets will show a pattern that resembles a straight line.[23] If a straight line is embedded into the scatter plot such that the average distance from all the points to the line is minimal, then the line is called a regression line. The equation of the regression line is called the regression equation.[24]
The regression equation is a linear equation; therefore, it has a slope and y-intercept. The format of the regression equation is .[25][lower-alpha 1]

- Let = the slope of the regression equation.


- Let = the y-intercept of the regression equation.


Suppose a sample of four observations of Celsius temperature measurements were taken 12 hours apart. At the same time, the thermometer was switched to Fahrenheit temperature and another measurement was taken.
- Let = a list of degrees Celsius data points of 30, 27, 31, 28.
- Let = a list of degrees Fahrenheit data points of 86.0, 80.6, 87.8, 82.4.
This R program will output the slope and y-intercept of the linear relationship between and :
x <- c( 30, 27, 31, 28 )
y <- c( 86.0, 80.6, 87.8, 82.4 )
# Build the numerator
independentDistanceFromMean <- x - mean( x )
sampledDependentDistanceFromMean <- y - mean( y )
independentDistanceTimesSampledDistance <-
independentDistanceFromMean *
sampledDependentDistanceFromMean
independentDistanceTimesSampledDistanceSum <-
sum( independentDistanceTimesSampledDistance )
# Build the denominator
independentDistanceFromMeanSquared <-
independentDistanceFromMean ** 2
independentDistanceFromMeanSquaredSum <-
sum( independentDistanceFromMeanSquared )
# Slope is rise over run
slope <-
independentDistanceTimesSampledDistanceSum /
independentDistanceFromMeanSquaredSum
yIntercept <- mean( y ) - slope * ( mean( x ) )
message( "Slope:" )
print( slope )
message( "Y-intercept" )
print( yIntercept )
Output:
Slope:
[1] 1.8
Y-intercept:
[1] 32
This R program will execute the native functions to output the slope and y-intercept:
x <- c( 30, 27, 31, 28 )
y <- c( 86.0, 80.6, 87.8, 82.4 )
# Execute lm() with Fahrenheit depends upon Celsius
linearModel <- lm( y ~ x )
# coefficients() returns a structure containing the slope and y intercept
coefficients <- coefficients( linearModel )
# Extract the slope from the structure
slope <- coefficients[["x"]]
# Extract the y intercept from the structure
yIntercept <- coefficients[["(Intercept)"]]
message( "Slope:" )
print( slope )
message( "Y-intercept" )
print( yIntercept )
Output:
Slope:
[1] 1.8
Y-intercept:
[1] 32
The coefficient of determination determines the percentage of variation explained by the independent variable.[26] It always lies between 0 and 1.[27] A value of 0 indicates no relationship between the two data sets, and a value near 1 indicates the regression equation is extremely useful for making predictions.[28]
- Let = the data set of predicted response data points when the independent data points are passed through the regression equation.
- Let = the coefficient of determination in a relationship between an independent variable and a dependent variable.



This R program will output the coefficient of determination of the linear relationship between and :
x <- c( 30, 27, 31, 28 )
y <- c( 86.0, 80.6, 87.8, 82.4 )
# Build the numerator
linearModel <- lm( y ~ x )
coefficients <- coefficients( linearModel )
slope <- coefficients[["x"]]
yIntercept <- coefficients[["(Intercept)"]]
predictedResponse <- yIntercept + ( slope * x )
predictedResponseDistanceFromMean <-
predictedResponse - mean( y )
predictedResponseDistanceFromMeanSquared <-
predictedResponseDistanceFromMean ** 2
predictedResponseDistanceFromMeanSquaredSum <-
sum( predictedResponseDistanceFromMeanSquared )
# Build the denominator
sampledResponseDistanceFromMean <- y - mean( y )
sampledResponseDistanceFromMeanSquared <-
sampledResponseDistanceFromMean ** 2
sampledResponseDistanceFromMeanSquaredSum <-
sum( sampledResponseDistanceFromMeanSquared )
coefficientOfDetermination <-
predictedResponseDistanceFromMeanSquaredSum /
sampledResponseDistanceFromMeanSquaredSum
message( "Coefficient of Determination:" )
print( coefficientOfDetermination )
Output:
Coefficient of Determination:
[1] 1
This R program will execute the native functions to output the coefficient of determination:
x <- c( 30, 27, 31, 28 )
y <- c( 86.0, 80.6, 87.8, 82.4 )
linearModel <- lm( y ~ x )
summary <- summary( linearModel )
coefficientOfDetermination <- summary[["r.squared"]]
message( "Coefficient of Determination:" )
print( coefficientOfDetermination )
Output:[lower-alpha 2]
Coefficient of Determination:
[1] 1
Single plot
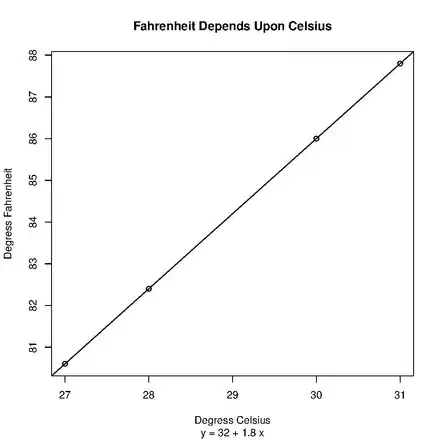
This R program will display a scatter plot with an embedded regression line and regression equation illustrating the relationship between and :
x <- c( 30, 27, 31, 28 )
y <- c( 86.0, 80.6, 87.8, 82.4 )
linearModel <- lm( y ~ x )
coefficients <- coefficients( linearModel )
slope <- coefficients[["x"]]
intercept <- coefficients[["(Intercept)"]]
# Execute paste() to build the regression equation string
regressionEquation <- paste( "y =", intercept, "+", slope, "x" )
# Display a scatter plot with the regression line and equation embedded
plot(
x,
y,
main = "Fahrenheit Depends Upon Celsius",
sub = regressionEquation,
xlab = "Degress Celsius",
ylab = "Degress Fahrenheit",
abline( linearModel ) )
Output:
Multi plot
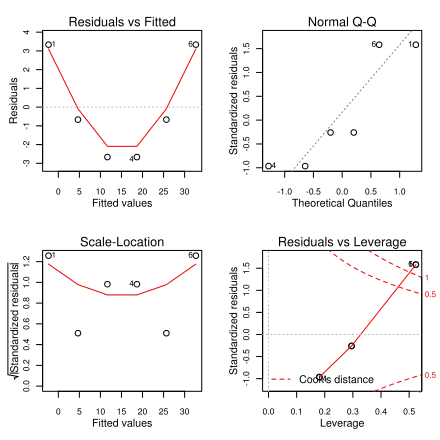
This R program will generate a multi-plot and a table of residuals.
# The independent variable is a list of numbers 1 to 6
x <- 1:6
# The dependent variable is a list of each independent variable squared
y <- x^2
# Linear regression model where y depends upon x
linearModel <- lm(y ~ x)
# Display the residuals
summary( linearModel )
# Create a 2 by 2 multi-plot
par(mfrow = c(2, 2))
# Output the multi-plot
plot( linearModel )
Output:
Residuals:
1 2 3 4 5 6 7 8 9 10
3.3333 -0.6667 -2.6667 -2.6667 -0.6667 3.3333
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -9.3333 2.8441 -3.282 0.030453 *
x 7.0000 0.7303 9.585 0.000662 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.055 on 4 degrees of freedom
Multiple R-squared: 0.9583, Adjusted R-squared: 0.9478
F-statistic: 91.88 on 1 and 4 DF, p-value: 0.000662
Mandelbrot graphic
This Mandelbrot set example highlights the use of complex numbers. It models the first 20 iterations of the equation z = z2 + c, where c represents different complex constants.
Install the package that provides the write.gif() function beforehand:
install.packages("caTools")
R program:
library(caTools)
jet.colors <-
colorRampPalette(
c("green", "pink", "#007FFF", "cyan", "#7FFF7F",
"white", "#FF7F00", "red", "#7F0000"))
dx <- 1500 # define width
dy <- 1400 # define height
C <-
complex(
real =
rep(
seq(-2.2, 1.0, length.out = dx), each = dy),
imag = rep(seq(-1.2, 1.2, length.out = dy),
dx))
# reshape as matrix of complex numbers
C <- matrix(C, dy, dx)
# initialize output 3D array
X <- array(0, c(dy, dx, 20))
Z <- 0
# loop with 20 iterations
for (k in 1:20) {
# the central difference equation
Z <- Z^2 + C
# capture the results
X[, , k] <- exp(-abs(Z))
}
write.gif(
X,
"Mandelbrot.gif",
col = jet.colors,
delay = 100)
Output:
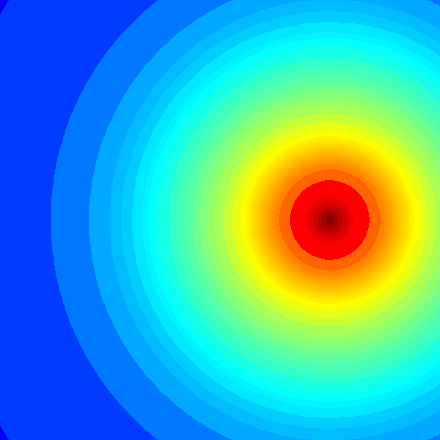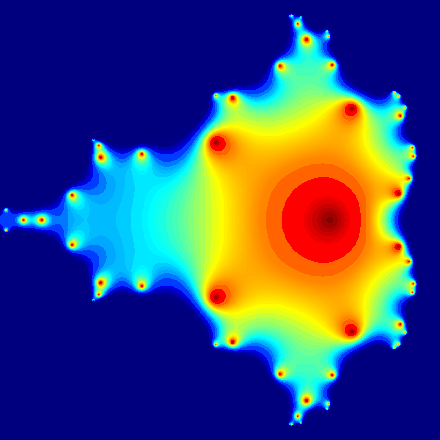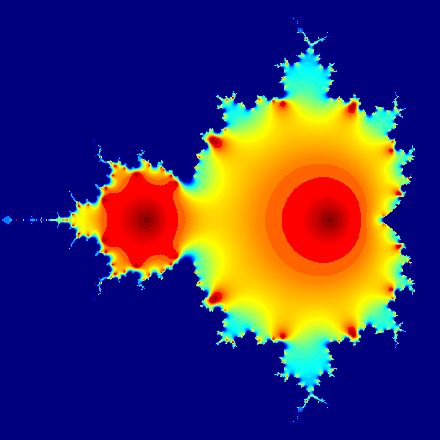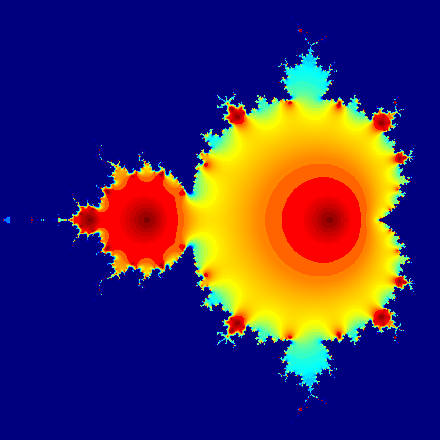
Programming
R is an interpreted language, so programmers typically access it through a command-line interpreter. If a programmer types 1+1 at the R command prompt and presses enter, the computer replies with 2.[29] Programmers also save R programs to a file then execute the batch interpreter Rscript.
Object
R stores data inside an object. An object is assigned a name which the computer program uses to set and retrieve the data.[30] An object is created by placing its name to the left of the symbol pair <-.[31]
To create an object named x and assign it the integer 82:
x <- 82L
print( x )
Output:
[1] 82
The [1] displayed before the number is a subscript. It shows the container for this integer is index one of an array.
Vector
The most primitive R object is the vector.[32] A vector is a one dimensional array of data. To assign multiple elements to the array, use the c() function to "combine" the elements. The elements must be the same data type.[33] R lacks scalar data types, which are placeholders for a single word — usually an integer. Instead, a single integer is stored into the first element of an array. The single integer is retrieved using the index subscript of [1].
R program to store and retrieve a single integer:
store <- 82L
retrieve <- store[1]
print( retrieve[1] )
Output:
[1] 82
Element-wise operation
When an operation is applied to a vector, R will apply the operation to each element in the array. This is called an element-wise operation.[34]
This example creates the object named x and assigns it integers 1 through 3. The object is displayed and then again with one added to each element:
x <- 1:3
print( x )
print( x + 1 )
Output:
[1] 1 2 3
[1] 2 3 4
To achieve the many additions, R implements vector recycling.[34] The number one following the + operation is converted into an internal array of three ones. The + operation simultaneously loops through both arrays and performs the addition on each element pair. The results are stored into another internal array of three elements which is returned to the print() function.
Numeric vector
A numeric vector is used to store integers and floating point numbers.[35] The primary characteristic of a numeric vector is the ability to perform arithmetic on the elements.[35]
Integer vector
By default, integers (numbers without a decimal point) are stored as floating point. To force integer memory allocation, append an L to the number. As an exception, the sequence operator : will, by default, allocate integer memory.
R program:
x <- 82L
print( x[1] )
message( "Data type:" )
typeof( x )
Output:
[1] 82
Data type:
[1] "integer"
R program:
x <- c( 1L, 2L, 3L )
print( x )
message( "Data type:" )
typeof( x )
Output:
[1] 1 2 3
Data type:
[1] "integer"
R program:
x <- 1:3
print( x )
message( "Data type:" )
typeof( x )
Output:
[1] 1 2 3
Data type:
[1] "integer"
Double vector
A double vector stores real numbers, which are also known as floating point numbers. The memory allocation for a floating point number is double precision.[35] Double precision is the default memory allocation for numbers with or without a decimal point.
R program:
x <- 82
print( x[1] )
message( "Data type:" )
typeof( x )
Output:
[1] 82
Data type:
[1] "double"
R program:
x <- c( 1, 2, 3 )
print( x )
message( "Data type:" )
typeof( x )
Output:
[1] 1 2 3
Data type:
[1] "double"
Logical vector
A logical vector stores binary data — either TRUE or FALSE. The purpose of this vector is to store the results of a comparison.[36] A logical datum is expressed as either TRUE, T, FALSE, or F.[36] The capital letters are required, and no quotes surround the constants.[36]
R program:
x <- 3 < 4
print( x[1] )
message( "Data type:" )
typeof( x )
Output:
[1] TRUE
Data type:
[1] "logical"
Character vector
A character vector stores character strings.[37] Strings are created by surrounding text in double quotation marks.[37]
R program:
x <- "hello world"
print( x[1] )
message( "Data type:" )
typeof( x )
Output:
[1] "hello world"
Data type:
[1] "character"
R program:
x <- c( "hello", "world" )
print( x )
message( "Data type:" )
typeof( x )
Output:
[1] "hello" "world"
Data type:
[1] "character"
Data frame
A data frame stores a two dimensional array of vectors. It is the most useful structure for data analysis.[38] Data frames are created using the data.frame() function. The input is a list of vectors (of any data type). Each vector becomes a column in a table. The elements in each vector are aligned to form the rows in the table.
R program:
integer <- c( 82L, 83L )
string <- c( "hello", "world" )
data.frame <- data.frame( integer, string )
print( data.frame )
message( "Data type:" )
class( data.frame )
Output:
integer string
1 82 hello
2 83 world
Data type:
[1] "data.frame"
Data frames can be deconstructed by providing a vector's name between double brackets. This returns the original vector. Each element in the returned vector can be accessed by its index number.
R program to extract the word "world". It is stored in the second element of the "string" vector:
integer <- c( 82L, 83L )
string <- c( "hello", "world" )
data.frame <- data.frame( integer, string )
vector <- data.frame[["string"]]
print( vector[2] )
message( "Data type:" )
typeof( vector )
Output:
[1] "world"
Data type:
[1] "character"
Functions
A function is an object that stores computer code instead of data.[39] The purpose of storing code inside a function is to be able to reuse it in another context.[39] To instantiate a function object, execute the function() statement and assign the results to a name.[40]
A function receives input both from global variables and input parameters (often called arguments). Objects created within the function body remain local to the function.
R code to create a function:
# The input parameters are x and y.
# The return value is a numeric double vector.
f <- function(x, y)
{
first_expression <- x * 2
second_expression <- y * 3
first_expression + second_expression
# The return statement may be omitted
# if the last expression is unassigned.
# This will save a few clock cycles.
}
Usage output:
> f(1, 2)
[1] 8
Function arguments are passed in by value.
R supports generic functions. They act differently depending on the classes of the arguments passed in. The process is to dispatch the method specific to the set of classes. A common implementation is R's print() function. It can print almost every class of object. For example, print(objectName).[41]
Packages
The R package is a collection of functions, documentation, and data that expand R.[42] As examples: packages add output features to more graphical devices, transform features to import and export data, and report features such as RMarkdown, knitr and Sweave. Easy package installation and use have contributed to the language's adoption in data science.[43]
Multiple packages are included with the basic installation. Additional packages are available on repositories: CRAN, R-Forge, Omegahat, and GitHub.
The Task Views on the CRAN website lists packages in fields including finance, genetics, high-performance computing, machine learning, medical imaging, meta-analysis, social sciences, and spatial statistics.
The bioconductor project provides packages for genomic data analysis, complementary DNA, microarray, and high-throughput sequencing methods.
Packages add the capability to interface with standalone, interactive graphics.[44]
Packages add the capability to implement various statistical techniques: linear, generalized linear and nonlinear modeling, classical statistical tests, spatial analysis, time-series analysis, and clustering.
The Tidyverse package is organized to have a common interface. Each function in the package is designed to couple together all the other functions in the package.[42]
Installing a package occurs only once. To install tidyverse:[42]
> install.packages( "tidyverse" )
To instantiate the functions, data, and documentation of a package, execute the library() function. To instantiate tidyverse:[lower-alpha 3]
> library( tidyverse )
Interfaces
R comes installed with a command line console. Available for installation are various integrated development environments (IDE). IDEs for R include R.app (OSX/macOS only), Rattle GUI, R Commander, RKWard, RStudio, and Tinn-R.
General purpose IDEs that support R include Eclipse via the StatET plugin and Visual Studio via R Tools for Visual Studio.
Editors that support R include Emacs, Vim via the Nvim-R plugin (website), Kate, LyX via Sweave, WinEdt (website), and Jupyter (website).
Scripting languages that support R include Python (website), Perl (website), Ruby (source code), F# (website), and Julia (source code).
General purpose programming languages that support R include Java via the Rserve socket server (website) and .NET C# (website).
Statistical frameworks which use R in the background include Jamovi and JASP.
Implementations
The main R implementation is written primarily in C, Fortran, and R itself. Several other implementations are aimed to improve speed or increase extensibility. For example, pqR (pretty quick R), by Radford M. Neal, has improved memory management and support for automatic multithreading. Renjin and FastR are Java implementations of R for use in a Java Virtual Machine. CXXR, rho, and Riposte[45] are implementations of R in C++. Renjin, Riposte, and pqR attempt to improve performance by using multiple cores and deferred evaluation.[46]
TIBCO, who previous sold the commercial implementation S-PLUS, built a runtime engine called TERR, which is part of Spotfire.[47]
Microsoft R Open (MRO) was a fully compatible R distribution with modifications for multi-threaded computations.[48] As of 30 June 2021, Microsoft started to phase out MRO in favor of the CRAN distribution.[49]
Community
The R community hosts many conferences and in-person meetups. Some of these groups include:
- UseR!: an annual international R user conference (website)
- Directions in Statistical Computing (DSC) (website)
- R-Ladies: an organization to promote gender diversity in the R community (website)
- SatRdays: R-focused conferences held on Saturdays (website)
- R Conference (website)
- Posit::conf (formerly known as Rstudio::conf) (website)
The R Journal
The R Journal is an open access, refereed journal of the R project. It features short to medium-length articles on the use and development of R, including packages, programming tips, CRAN news, and foundation news.
Commercial support
Although R is an open-source project, some companies provide commercial support:
See also
Notes
- ↑ The format of the regression equation differs from the algebraic format of . The y-intercept is placed first, and all of the independent variables are appended to the right.
- ↑ This may display to standard error a warning message that the summary may be unreliable. Nonetheless, the output of 1 is correct.
- ↑ This displays to standard error a listing of all the packages that tidyverse depends upon. It may also display two errors showing conflict. The errors may be ignored.

References
- 1 2 3 Morandat, Frances; Hill, Brandon; Osvald, Leo; Vitek, Jan (11 June 2012). "Evaluating the design of the R language: objects and functions for data analysis". European Conference on Object-Oriented Programming. 2012: 104–131. doi:10.1007/978-3-642-31057-7_6. Retrieved 17 May 2016 – via SpringerLink.
- ↑ Peter Dalgaard (31 October 2023). "R 4.3.2 is released". Retrieved 2 November 2023.
- ↑ "R scripts". mercury.webster.edu. Retrieved 17 July 2021.
- ↑ "R Data Format Family (.rdata, .rda)". Loc.gov. 9 June 2017. Retrieved 17 July 2021.
- 1 2 Hornik, Kurt; The R Core Team (12 April 2022). "R FAQ". The Comprehensive R Archive Network. 3.3 What are the differences between R and S?. Archived from the original on 28 December 2022. Retrieved 27 December 2022.
- ↑ "Introduction". The Julia Manual. Archived from the original on 20 June 2018. Retrieved 5 August 2018.
- ↑ Giorgi, Federico M.; Ceraolo, Carmine; Mercatelli, Daniele (27 April 2022). "The R Language: An Engine for Bioinformatics and Data Science". Life. 12 (5): 648. Bibcode:2022Life...12..648G. doi:10.3390/life12050648. PMC 9148156. PMID 35629316.
- ↑ Ihaka, Ross. "The R Project: A Brief History and Thoughts About the Future" (PDF). p. 12. Archived (PDF) from the original on 28 December 2022. Retrieved 27 December 2022.
- ↑ Hornik, Kurt; The R Core Team (12 April 2022). "R FAQ". The Comprehensive R Archive Network. 2.13 What is the R Foundation?. Archived from the original on 28 December 2022. Retrieved 28 December 2022.
- ↑ Ihaka, Ross. "R: Past and Future History" (PDF). p. 4. Archived (PDF) from the original on 28 December 2022. Retrieved 28 December 2022.
- ↑ Maechler, Martin (1 April 1997). ""R-announce", "R-help", "R-devel" : 3 mailing lists for R". stat.ethz.ch. Archived from the original on 16 November 2022. Retrieved 12 February 2023.
- ↑ Ihaka, Ross (5 December 1997). "New R Version for Unix". stat.ethz.ch. Archived from the original on 12 February 2023. Retrieved 12 February 2023.
- ↑ Ihaka, Ross. "The R Project: A Brief History and Thoughts About the Future" (PDF). p. 18. Archived (PDF) from the original on 28 December 2022. Retrieved 27 December 2022.
- 1 2 Hornik, Kurt (2012). "The Comprehensive R Archive Network". WIREs Computational Statistics. 4 (4): 394–398. doi:10.1002/wics.1212. ISSN 1939-5108. S2CID 62231320.
- ↑ Kurt Hornik (23 April 1997). "Announce: CRAN". r-help. Wikidata Q101068595..
- ↑ "The Status of CRAN Mirrors". cran.r-project.org. Retrieved 30 December 2022.
- ↑ "CRAN - Contributed Packages". cran.r-project.org. Retrieved 29 December 2022.
- 1 2 Hornik, Kurt; R Core Team (12 April 2022). "R FAQ". 2.1 What is R?. Archived from the original on 28 December 2022. Retrieved 29 December 2022.
- 1 2 3 Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 90. ISBN 0-201-71058-7.
- 1 2 Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 105. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 155. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 146. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 148. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 156. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 157. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 170. ISBN 0-201-71058-7.
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 175. ISBN 0-201-71058-7.
The coefficient of determination always lies between 0 and 1 ...
- ↑ Weiss, Neil A. (2002). Elementary Statistics, Fifth Edition. Addison-Wesley. p. 175. ISBN 0-201-71058-7.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 4. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 7. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 8. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 37. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 38. ISBN 978-1-449-35901-0.
- 1 2 Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 10. ISBN 978-1-449-35901-0.
- 1 2 3 Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 39. ISBN 978-1-449-35901-0.
- 1 2 3 Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 42. ISBN 978-1-449-35901-0.
- 1 2 Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 41. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 55. ISBN 978-1-449-35901-0.
- 1 2 Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 16. ISBN 978-1-449-35901-0.
- ↑ Grolemund, Garrett (2014). Hands-On Programming with R. O'Reilly. p. 17. ISBN 978-1-449-35901-0.
- ↑ R Core Team. "Print Values". R Documentation. R Foundation for Statistical Computing. Retrieved 30 May 2016.
- 1 2 3 Wickham, Hadley; Cetinkaya-Rundel, Mine; Grolemund, Garrett (2023). R for Data Science, Second Edition. O'Reilly. p. xvii. ISBN 978-1-492-09740-2.
- ↑ Chambers, John M. (2020). "S, R, and Data Science". The R Journal. 12 (1): 462–476. doi:10.32614/RJ-2020-028. ISSN 2073-4859.
The R language and related software play a major role in computing for data science. ... R packages provide tools for a wide range of purposes and users.
- ↑ Lewin-Koh, Nicholas (7 January 2015). "CRAN Task View: Graphic Displays & Dynamic Graphics & Graphic Devices & Visualization". Archived from the original on 26 September 2016. Retrieved 27 December 2022.
There are several efforts to implement interactive graphics systems that interface well with R.
- ↑ Talbot, Justin; DeVito, Zachary; Hanrahan, Pat (1 January 2012). "Riposte: A trace-driven compiler and parallel VM for vector code in R". Proceedings of the 21st international conference on Parallel architectures and compilation techniques. ACM. pp. 43–52. doi:10.1145/2370816.2370825. ISBN 9781450311823. S2CID 1989369.
- ↑ Neal, Radford (25 July 2013). "Deferred evaluation in Renjin, Riposte, and pqR". Radford Neal's blog. Retrieved 6 March 2017.
- ↑ Jackson, Joab (16 May 2013). TIBCO offers free R to the enterprise. PC World. Retrieved 20 July 2015.
- ↑ "Microsoft R Open: The Enhanced R Distribution". Archived from the original on 16 June 2018. Retrieved 30 June 2018.
- ↑ "Looking to the future for R in Azure SQL and SQL Server". 30 June 2021. Retrieved 7 November 2021.
External links
- Official website
 of the R project
of the R project - R Technical Papers
- Free Software Foundation
- R FAQ
| Features | ||
|---|---|---|
| Implementations |
| |
| Packages | ||
| Interfaces | ||
| People | ||
| Organisations | ||
| Publications | ||
|