
In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).[1]
For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as

Note that should be the "raw" output of the classifier's decision function, not the predicted class label. For instance, in linear SVMs, , where are the parameters of the hyperplane and is the input variable(s).




When t and y have the same sign (meaning y predicts the right class) and , the hinge loss . When they have opposite signs, increases linearly with y, and similarly if , even if it has the same sign (correct prediction, but not by enough margin).




Extensions
While binary SVMs are commonly extended to multiclass classification in a one-vs.-all or one-vs.-one fashion,[2] it is also possible to extend the hinge loss itself for such an end. Several different variations of multiclass hinge loss have been proposed.[3] For example, Crammer and Singer[4] defined it for a linear classifier as[5]
- ,

where is the target label, and are the model parameters.



Weston and Watkins provided a similar definition, but with a sum rather than a max:[6][3]
- .

In structured prediction, the hinge loss can be further extended to structured output spaces. Structured SVMs with margin rescaling use the following variant, where w denotes the SVM's parameters, y the SVM's predictions, φ the joint feature function, and Δ the Hamming loss:
- .

Optimization
The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has a subgradient with respect to model parameters w of a linear SVM with score function that is given by


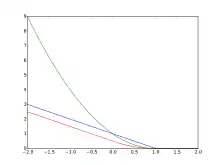
However, since the derivative of the hinge loss at is undefined, smoothed versions may be preferred for optimization, such as Rennie and Srebro's[7]


or the quadratically smoothed

suggested by Zhang.[8] The modified Huber loss is a special case of this loss function with , specifically .



See also
References
- ↑ Rosasco, L.; De Vito, E. D.; Caponnetto, A.; Piana, M.; Verri, A. (2004). "Are Loss Functions All the Same?" (PDF). Neural Computation. 16 (5): 1063–1076. CiteSeerX 10.1.1.109.6786. doi:10.1162/089976604773135104. PMID 15070510.
- ↑ Duan, K. B.; Keerthi, S. S. (2005). "Which Is the Best Multiclass SVM Method? An Empirical Study" (PDF). Multiple Classifier Systems. LNCS. Vol. 3541. pp. 278–285. CiteSeerX 10.1.1.110.6789. doi:10.1007/11494683_28. ISBN 978-3-540-26306-7.
- 1 2 Doğan, Ürün; Glasmachers, Tobias; Igel, Christian (2016). "A Unified View on Multi-class Support Vector Classification" (PDF). Journal of Machine Learning Research. 17: 1–32.
- ↑ Crammer, Koby; Singer, Yoram (2001). "On the algorithmic implementation of multiclass kernel-based vector machines" (PDF). Journal of Machine Learning Research. 2: 265–292.
- ↑ Moore, Robert C.; DeNero, John (2011). "L1 and L2 regularization for multiclass hinge loss models" (PDF). Proc. Symp. on Machine Learning in Speech and Language Processing.
- ↑ Weston, Jason; Watkins, Chris (1999). "Support Vector Machines for Multi-Class Pattern Recognition" (PDF). European Symposium on Artificial Neural Networks.
- ↑ Rennie, Jason D. M.; Srebro, Nathan (2005). Loss Functions for Preference Levels: Regression with Discrete Ordered Labels (PDF). Proc. IJCAI Multidisciplinary Workshop on Advances in Preference Handling.
- ↑ Zhang, Tong (2004). Solving large scale linear prediction problems using stochastic gradient descent algorithms (PDF). ICML.