| Part of a series on |
| Forensic science |
|---|
.png.webp) |
|
Audio forensics is the field of forensic science relating to the acquisition, analysis, and evaluation of sound recordings that may ultimately be presented as admissible evidence in a court of law or some other official venue.[1][2][3][4]
Audio forensic evidence may come from a criminal investigation by law enforcement or as part of an official inquiry into an accident, fraud, accusation of slander, or some other civil incident.[5]
The primary aspects of audio forensics are establishing the authenticity of audio evidence, performing enhancement of audio recordings to improve speech intelligibility and the audibility of low-level sounds, and interpreting and documenting sonic evidence, such as identifying talkers, transcribing dialog, and reconstructing crime or accident scenes and timelines.[2]
Modern audio forensics makes extensive use of digital signal processing, with the former use of analog filters now being obsolete. Techniques such as adaptive filtering and discrete Fourier transforms are used extensively.[3] Recent advances in audio forensics techniques include voice biometrics and electrical network frequency analysis.[6]
History
The possibility of performing forensic audio analysis depends on the availability of audio recordings made outside the boundaries of a recording studio. The first portable magnetic tape recorders appeared in the 1950s and soon these devices were used to obtain clandestine recordings of interviews and wiretaps, as well as to record interrogations.[4]
The first legal case that invoked the forensic audio techniques in the U.S. federal courts was the United States v. McKeever case, which took place in the 1950s.[7] For the first time, the judge in the McKeever case was asked to determine the legal admissibility of the conversation recorded that involved the defendant.[8]
The US Federal Bureau of Investigation (FBI) started implementing audio forensic analysis and audio enhancement in the early 1960s.[4]
The field of audio forensics was primarily established in 1973 during the Watergate scandal. A federal court commissioned a panel of audio engineers to investigate the gaps in President Nixon's Watergate Tapes, which were secret recordings U.S. President Richard Nixon made while in office. The probe found nine separate sections of a vital tape had been erased. The report gave rise to new techniques to analyze magnetic tape.[6]
Authenticity
A digital audio recording may introduce many challenges for authenticity evaluation.[9] Authenticity analysis of digital audio recordings is based on traces left within the recording during the recording process, and by other subsequent editing operations. The first goal of the analysis is to detect and identify which of these traces can be retrieved from the audio recording, and to document their properties.[10] In a second step, the properties of the retrievable traces are analysed to determine if they support or oppose the hypothesis that the recording has been modified.
To access the authenticity of audio evidence the examiner needs several types of observation, such as: checking recording capability, recording format, reviewing document history, listen the entire audio.[11]
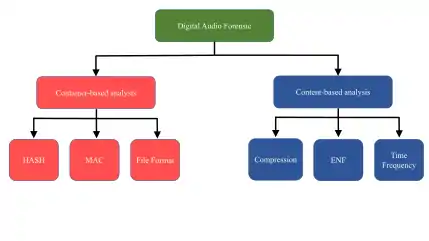
The methods to access the digital audio integrity can be divided into two main categories:[8]
- Container-based technique
- Content-based technique
Container analysis
The container analysis consists of HASH calculation, MAC and File format analysis.[8]
- Hash analysis: A unique character string is derived from the bits and bytes of the audio file and calculated by a mathematically derived hash function. These can be useful to verify that no modifications have occurred to a file from the moment of its HASH calculation is done to the next instance of HASH calculation.
- MAC time stamps: Using MAC time stamps the examiner can detect the date and time of creation of the file and of its modifications, as well as its last access time. The MAC time stamps are generated by the interlock of the digital system, but this can be corrupted by using a copy/transfer operation or through editing operations.
- File Format: Analysis of some audio parameters embedded in the audio format (codec, sample rate, bit depth, etc..).
- Header: Scientists can detect a change in the recording using the header information of the file format. Depending on the device and brand, there may be information about the model, serial number, firmware version, time, date and length of the recording (as determined by the internal clock settings). It is useful to note the time stamps and compare them to the date and time claimed by the recordists as to when the file was made.[12]
- Hex data: The raw digital data of the file may contain useful information that can be examined in a hexadecimal reader with an ASCII character viewer. Block addresses of audio information, titles of external software, post-processing operations and other useful information may be displayed.[13]
Content analysis
The content analysis is the central part of the digital forensic analysis process and it is based on the content of the audio file to find traces of manipulation and anti-forensic processing operations. The content-based audio forensic techniques can be split in the following categories:
- Electrical Network Frequency (ENF)
- Acoustic environment signature
The ENF
Main article: Electrical Network Frequency analysis

The Electrical Network Frequency is one of the most trusted and robust audio forensic analyses.[8]
All digital recording devices are sensitive to the induced frequency of the power supply at 50 or 60 Hz, which in turn provides an identifiable waveform signature within the recording. This applies to both mains-powered units and portable devices when the latter are used in proximity of transmission cables or mains-powered equipment.[14]
The ENF feature vector is obtained using a band‑pass filtering between the range 49‑51 Hz, without resampling the audio file, to separate the ENF waveform from the original recording. The results then are plotted and analyzed against the database provided by the power supplier to prove or disprove the recording's integrity, thus providing evidential and scientific authentication of the material in analysis.[14]
The Acoustic Environment Signature
Main article: Acoustic signature
An audio recording is usually a combination of multiple acoustic signals, such as: direct sources, indirect signals or reflections, secondary sources, and ambient noise. The indirect signals, secondary sources and ambient noise are used to characterize an acoustic environment.[4] The hard work is to extrapolate the acoustic cues from the audio recording.
Dynamic Acoustic Environment Identification (AEI) can be computed using an estimate of the reverberation and the background noise.[8]
Audio Enhancement
Audio enhancement is a forensic process that aims at improving the audio file intelligibility by removing and cleaning unwanted noise from an otherwise unintelligible recording.[2]
The forensic scientists try to remove these noises without affecting the original information present in the audio file. Enhancement allows to obtain a better intelligibility of the file, that can be crucial to determine the participation or not of a person in a crime.[8]
The core of the audio enhancement analysis is to detect noise problems and extract it from the original file. In fact, if the noise can be reverse‑engineered in some way it can be exploited and researched to allow for its subsequent removal or attenuation.[14]
The goals of forensic audio enhancement are:
- Increase the accuracy in transcriptions
- Decrease listeners' fatigue
- Increase speech intelligibility
- Increase SNR
The first step of the audio enhancement process is critical listening: the complete recording is reviewed, in order to formulate a sound forensic strategy. Creating clones of the audio recording is essential, since work is never conducted on the master recording in order to have the original file and be able to compare with it. Throughout the complete enhancement process, the original is constantly referenced against the original, unprocessed recording, thus preventing any over‑processing and pre‑empting issues that may be raised later within a trial. Following the guidelines and working procedures allows a different specialist to achieve the same results using the same processing.[14]
We can divide the interfering sound into two categories: stationary noise or time-variant noise.
The stationary noise has a consistent character, such as a continuous whine, hum, rumble, or hiss. Suppose the stationary noise occupies a frequency range that differs from the signals of interest, such as a speech recording with a steady rumble in the frequency range below 100 Hz. In that case, it can be possible to apply a fixed filter, such as a bandpass filter, to pass approximately the speech bandwidth. Usually the speech bandwidth ranges from 250 Hz to 4 kHz.[15] In case the stationary noise bandwidth occupies the same frequency range of the desired signal, a simple separation filter will not be helpful. However, it may still be possible to apply equalization to improve the audibility/intelligibility of the desired signal.[4]
The time-variant noise sources generally require more complicated processing than stationary noise sources and are often not effectively suppressed.[4]
Enhancement method
Audio enhancement is realized with both time-domain, automatic gain control, and frequency-domain methods, frequency selective filters and spectral subtraction.[16]
Automatic gain control
Time-domain enhancement usually involves gain adjustments to normalize the amplitude envelope of the recorded audio signal. Typically is used the automatic gain control technique, or gain compression/expansion technique, that tries to reach a constant sound level during the playback: portions of the recording referable only to noise are made quieter, low-amplitude signal passages are amplified, and loud passages are attenuated or left alone.
A common approach is to apply a noise gate or squelch process on the noisy signal. The noise gate can be realized as either an electronic device designed for the purpose, or it can be a software for processing with a computer. The noise gate compares the short-time level of its input signal with a pre-determined level threshold. If the signal level is above the threshold level, the gate opens, and the signal is let through, otherwise if the signal level is below the threshold, the gate closes and the signal is not allowed to pass. The role of the examiner is to adjust the threshold level so that the speech can pass through the gate while the noise signal, that occurs in the silence parts, is blocked. A noise gate can help the listener understand a signal that is perceived to be less noisy because the background sound is gated off during pauses in the conversation. However, the noise gate in its simple version cannot reduce the noise level and simultaneously boost the signal when both are present at the same time and the gate is open.[2]
Then there exist also more advanced noise gate systems that take advantage of some digital signal processing techniques to execute a gating separation in different frequency bands. These advanced systems help the examiner to remove particular types of noise and hiss present in the audio recording.[16]
Frequency-selective filters
The frequency-selective filters is a technique that operates in the frequency domain. The principle behind this technique is to enhance the quality of a recording by selectively attenuating tonal components in the spectrum, such as power-related hum and buzz signals. The use of a multi-band audio equalizer can also be helpful in reducing out-of-band noise while still retaining the frequency band of interest, such as the speech frequency range.[16]
Spectral subtraction
The spectral subtraction is a digital signal processing technique in which a short-term noise spectrum is estimated from a frame, and then subtracted from the spectrum of short frames of the noisy input signal. The spectrum obtained after the subtraction is used to reconstruct the noise-reduced frame of the output signal. The process continues for subsequent frames to create the entire output signal via an overlap-add procedure.[17]
The effectiveness of the spectral subtraction relies on the ability to estimate the noise spectrum. The estimate is usually obtained from an input signal frame that is known to contain only the background noise, such as a pause between sentences in a recorded conversation. The most sophisticated noise reduction methods combine the concepts of level detection in the time domain and spectral subtraction in the frequency domain. Additional signal models and rules are used to separate signal components that are most likely part of the desired signal from those that are likely to be additive noise.[16]
Interpretation
After authentication and enhancement, the audio file examined must be evaluated and interpreted to determine its importance for the investigation.[16]
For example in the case of a speech recording this means preparing a transcription of the audio content, identifying the talkers, interpreting the background sounds, and so on.[16]
In 2009, the US National Academy of Sciences (NAS) published a report entitled Strengthening Forensic Science in the United States: A Path Forward.[18] The report was highly critical of the many areas of forensic science, including audio forensics, that has traditionally relied upon subjective analysis and comparison.
The importance and reliability of forensic evidence depend upon a variety of contributions to an investigation. Some level of uncertainty is nearly always present, because usually the audio forensic evidence is interpreted with objective and subjective considerations.
While in a scientific study uncertainty can be measured with some indicators, and ongoing analysis may provide additional insights in the future, a forensic examination is not usually subject to ongoing review. The judgment needs to be made at the time the case is heard, so the court needs to weigh the various pieces of evidence and assess whatever level of doubt there may be. [19]
See also
References
- ↑ Phil Manchester (January 2010). "An Introduction To Forensic Audio". Sound on Sound.
- 1 2 3 4 Maher, Robert C. (March 2009). "Audio forensic examination: authenticity, enhancement, and interpretation". IEEE Signal Processing Magazine. 26 (2): 84–94. doi:10.1109/msp.2008.931080. S2CID 18216777.
- 1 2 Alexander Gelfand (10 October 2007). "Audio Forensics Experts Reveal (Some) Secrets". Wired Magazine. Archived from the original on 2012-04-08.
- 1 2 3 4 5 6 Maher, Robert C. (2018). Principles of forensic audio analysis. Cham, Switzerland: Springer. ISBN 9783319994536. OCLC 1062360764.
- ↑ Maher, Robert C. (Summer 2015). "Lending an ear in the courtroom: forensic acoustics" (PDF). Acoustics Today. 11: 22–29.
- 1 2 Williams, Christopher (June 1, 2010). "Met lab claims 'biggest breakthrough since Watergate'". The Register. Retrieved September 15, 2021.
- ↑ United States District Court, Southern District, New York. (1958). U.S. v. McKeever, 169 F. Supp. 426 (S.D.N.Y. 1958).
- 1 2 3 4 5 6 Zakariah, Mohammed; Khan, Muhammad Khurram; Malik, Hafiz (2017-01-09). "Digital multimedia audio forensics: past, present and future". Multimedia Tools and Applications. 77 (1): 1009–1040. doi:10.1007/s11042-016-4277-2. ISSN 1380-7501. S2CID 254830683.
- ↑ Brixen, E.B. (2007). "Techniques for the authentication of digital audio recordings". In Proceedings Audio Engineering Society 122nd Convention. Vienna, Austria.
- ↑ "Audio Cleanup Service - Media Restoration". Media Medic. Retrieved 2023-12-28.
- ↑ Koenig, BE (1990). "Authetication of forensic audio recordings". J Audio Eng Soc. 38: 3–33.
- ↑ Koenig, BE; Lacey, DS (2012). "Forensic authenticity analyses of the header data in re-encoded WMA files from small Olympus audio recorders". J Audio Eng Soc. 60: 255–265.
- ↑ Koenig, BE; Lacey, DS (2009). "Forensic authentication of digital audio recordings". J Audio Eng Soc. 57: 662–695.
- 1 2 3 4 "An Introduction To Forensic Audio". www.soundonsound.com. Retrieved 2022-06-28.
- ↑ "Definition: Voice frequency".
- 1 2 3 4 5 6 Maher, Robert C. (2010). "Overview of Audio Forensics". Intelligent Multimedia Analysis for Security Applications. Studies in Computational Intelligence. Vol. 282. pp. 127–144. doi:10.1007/978-3-642-11756-5_6. ISBN 978-3-642-11754-1.
- ↑ Boll, S. (1979). "A spectral subtraction algorithm for suppression of acoustic noise in speech". ICASSP '79. IEEE International Conference on Acoustics, Speech, and Signal Processing. Vol. 4. Institute of Electrical and Electronics Engineers. pp. 200–203. doi:10.1109/icassp.1979.1170696.
- ↑ US National Academy of Sciences (NAS). "Strengthening Forensic Science in the United States: A Path Forward" (PDF).
- ↑ Morrison, Geoffrey Stewart (2011). "Measuring the validity and reliability of forensic likelihood-ratio systems". Science & Justice. 51 (3): 91–98. doi:10.1016/j.scijus.2011.03.002. ISSN 1355-0306. PMID 21889105.